AWS Storage Blog
MemQ by Pinterest: An efficient, scalable, cloud-native publish/subscribe system
The Logging Platform at Pinterest powers all data ingestion and transportation at Pinterest. At the heart of the Pinterest Logging Platform are distributed pub/sub systems that help our customers transport, buffer, and consume data asynchronously. Pub/sub messaging, is a form of asynchronous service-to-service communication used in serverless and microservices architectures. In a pub/sub model, any message published to a topic is immediately received by all the subscribers to the topic. Pub/sub messaging can be used to enable event-driven architectures, or to decouple applications to increase performance, reliability and scalability.
In this post, I discuss MemQ, an efficient, scalable pub/sub system developed for the cloud and leveraging Amazon Simple Storage Service (S3) for data storage at Pinterest. MemQ has been powering near-real-time data transportation use cases for us since mid-2020, and complements Kafka, our legacy pub/sub system, while being over 90% more cost-efficient in some cases. To read more about MemQ, read the Pinterest engineering post.
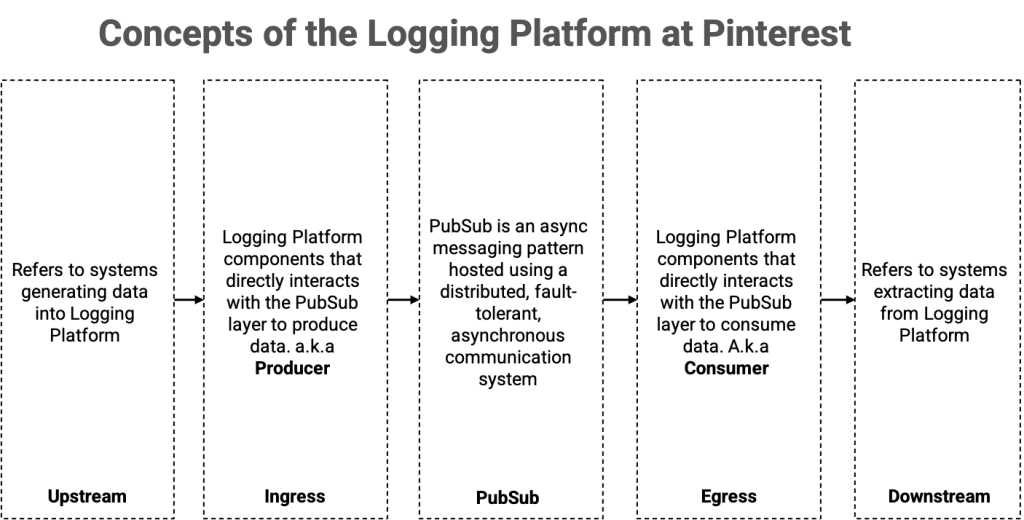
History
For nearly a decade, Pinterest has relied on Kafka as our sole pub/sub system. As Pinterest grew, so did the amount of data and the challenges for operating a very large-scale distributed pub/sub platform. Operating Kafka at scale gave us a great deal of insight into how to build a scalable pub/sub system. Upon deep investigation of the operational and scalability challenges of our pub/sub environment, we arrived at the following key takeaways:
- Not every dataset needs subsecond latency service; this is an opportunity to define near-real-time service class
- Storage and serving components of a pub/sub system need to be separated to enable independent scalability based on resources
- The scalability challenges of Kafka were closely related to the constraints of strict partition ordering, which weren’t necessary at Pinterest in most cases
- Rebalancing in Kafka is expensive, often results in performance degradation, and has a negative impact for customers on a saturated cluster
- Running custom replication in a cloud environment is expensive
In 2018, we experimented with a new type of pub/sub system that would use the cloud natively. In 2019, we started formally exploring how to solve our pub/sub scalability challenges. We evaluated multiple pub/sub technologies and even considered options to redesign Kafka to meet the demands of Pinterest. We finally determined that we needed a new generation of pub/sub technology that built on the learnings of Apache Kafka, Apache Pulsar, and Facebook LogDevice, and built it for the cloud.
![]()
MemQ is a new pub/sub system that augments Kafka at Pinterest. It offers a near-real-time class pub/sub service with end-to-end latency as low as 10 seconds. It uses a decoupled storage and a serving model similar to Apache Pulsar and Facebook LogDevice, but it relies on an external replicated object store or distributed file system like Amazon S3 for storing data. The net result is a pub/sub system with the following attributes:
- Can handle GB/s traffic
- Can scale writes and reads independently
- Doesn’t require expensive rebalancing to handle traffic growth
- Is over 90% more cost-effective than our Kafka footprint
The following diagram illustrates the workflow of our system.
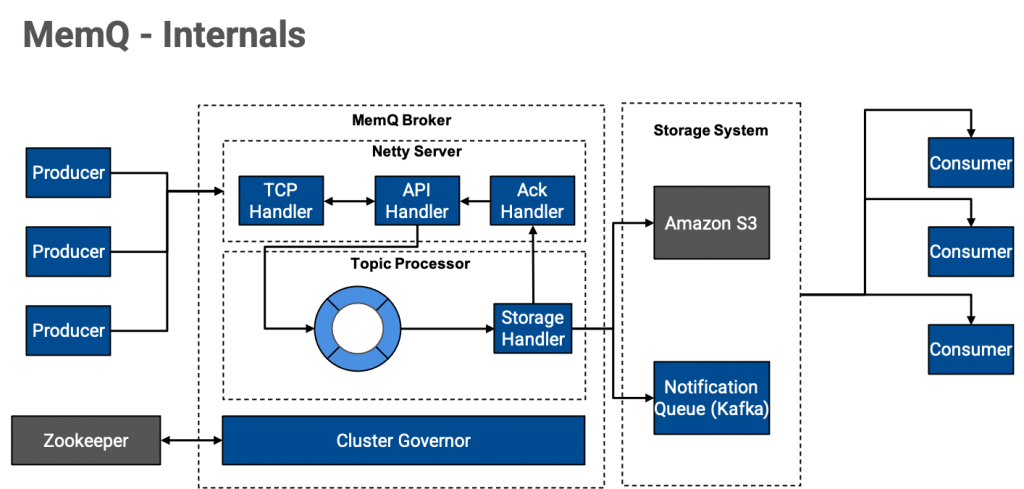
MemQ uses micro-batching and immutable writes to create an architecture where the number of IOPS necessary on the storage layer are dramatically reduced. This allows for an even more cost-effective use of a cloud-native object store like Amazon S3, and supports elastic on-demand scaling, and requires less maintenance.
Amazon S3 offers an extremely cost-effective solution for fault tolerant on-demand storage. However, IOPS on Amazon S3 can become expensive quickly. To use Amazon S3 efficiently, we have to reduce the number of IOPS.
MemQ breaks the continuous stream of logs into blocks (objects). It adds salting on the write paths to prevent hotspots and backpressure because the data is written as packets, which can be written independently to the storage system. The size of these packets, known internally in MemQ as a batch, play a role in determining the end-to-end latency. The smaller the packets, the faster they can be written, at the cost of more IOPS.
This essentially eliminated the constraints experienced in Kafka where in order to recover a replica, a partition must be re-replicated from the beginning. With MemQ, the underlying replicated storage only needs to recover the specific batch whose replica counts were reduced due to faults in case of storage failures. However, because MemQ at Pinterest runs on Amazon S3, the recovery, sharding, and scaling of storage is handled by AWS, without any manual intervention from Pinterest.
This approach is analogous to circuit switching vs. packet switching for networks.
MemQ data format
MemQ uses a custom storage and network transmission format for messages and batches, as illustrated in the following diagram.
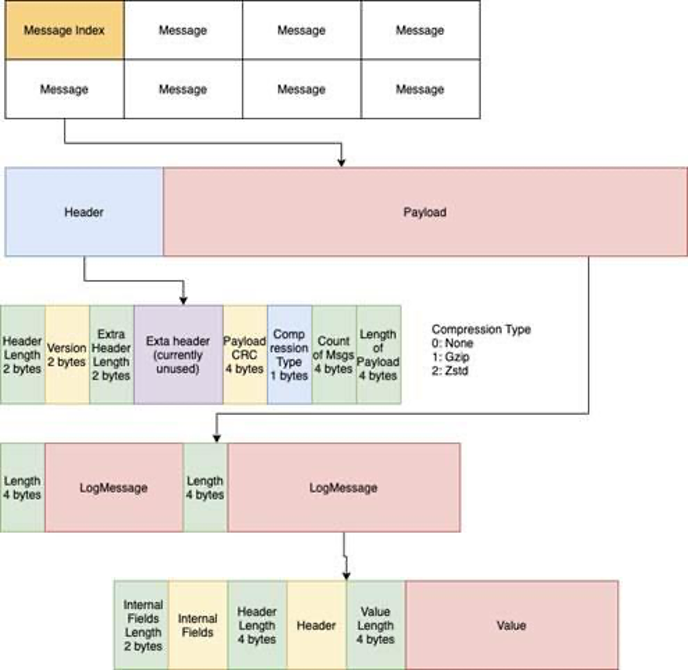
The lowest unit of transmission in MemQ is called a LogMessage, which is similar to a pulsar message or Kafka ProducerRecord.
The wrappers on the LogMessage allow for the different levels of batching that MemQ does.
LogMessages are collected together to create a message, which is the unit of send to a MemQ broker.
Messages on the broker are collected together to create a batch, which is the unit of persistence on the storage layer and also the unit of receive on the consumer. The levels of batching are necessary to enable efficiency and dynamic tuning for a topic.
Client and cluster
The MemQ client discovers the cluster using a seed node. It connects to the seed node to discover metadata and the brokers hosting the TopicProcessors for a given topic or, in the case of the consumer, the address of the notification queue.
Broker
Similar to other pub/sub systems, MemQ has the concept of a broker. A MemQ broker is a part of the cluster (if running in cluster mode) and is primarily responsible for handling metadata and write requests.
Read requests in MemQ are handled by the storage layer directly.
Netty server
MemQ relies heavily on Netty for both client, server, and storage-layer communication, as well as off-heap memory management.
Topic and topic processor
Similar to other pub/sub systems, MemQ uses the logical concept of a topic. MemQ topics are handled by a module called TopicProcessor on a broker. A broker can host one or more TopicProcessors, where each TopicProcessor instance handles one topic. Topics have write and read partitions. The write partitions are used to create TopicProcessors (1:1 relation), and the read partitions are used to determine the level of parallelism needed by the consumer to process the data. The read partition count is equal to the number of partitions of the notification queue.
Storage
MemQ storage is made of two parts:
- Replicated storage (the object store or distributed file system)
- Notification queue (such as Kafka or Pulsar)
Replicated storage
MemQ allows for pluggable storage handlers. As of this writing, we have implemented a storage handler for Amazon S3. MemQ uses the following S3 prefix to create the high-throughput storage layer:
s3://<bucketname>/<2 byte hash of first client request id in batch>/< name of MemQ cluster>/topics/<topicname>. Because Amazon S3 is a highly available web-scale object store, MemQ relies on its availability as the first line of defense. To accommodate for future Amazon S3 repartitioning, MemQ adds a two-digit hex hash at the first level of the prefix, creating 256 base prefixes that can in theory be handled by independent S3 partitions, just to make it future proof.
The consistency of the underlying storage layer determines the consistency characteristics of MemQ. In the case of Amazon S3, every write (PUT) to Amazon S3 Standard storage is guaranteed to be replicated to at least three Availability Zones before being acknowledged. As of December 2020, Amazon S3 delivers strong read-after-write consistency.
Notification queue
MemQ uses a notification system to deliver pointers to the consumer for the location of data. As of this writing, we use an external notification queue in the form of Kafka. When data is uploaded to the storage layer, the storage handler generates a notification message recording the attributes of the upload, including its location, size, topic, and more. This information is used by the consumer to retrieve data (batches) from the storage layer.
Performance numbers
In this section, we present some latency metrics. The following is an example of the largest Kafka use case by volume operating on MemQ in production, and shows the latency performance of MemQ on Amazon S3.
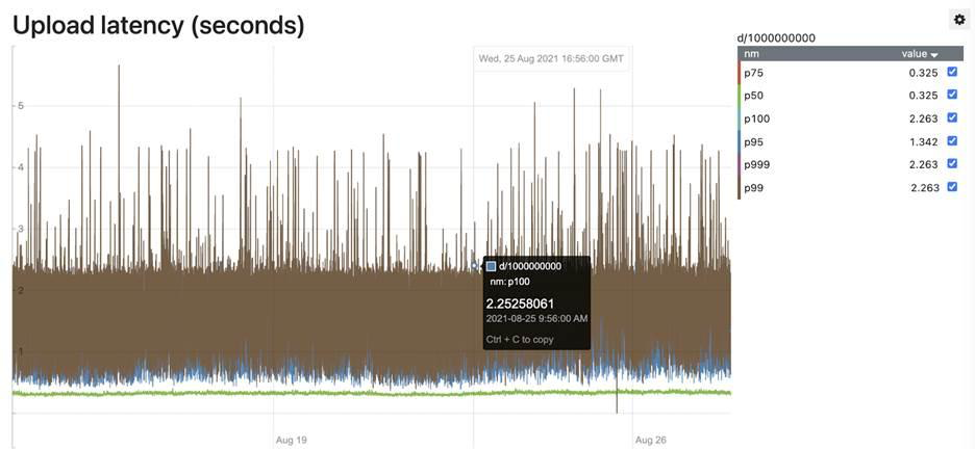
Even under load, MemQ is able to keep tail latencies under check.
With the micro-batching design, MemQ is susceptible to higher latencies compared to Kafka because the storage isn’t local and the service is optimized for throughput and cost-efficiency, generally not latency. MemQ supports both size- and time-based flushes to the storage layer, which enables a hard limit on max tail latencies, in addition to several optimizations to curb the jitter.
In general, MemQ size-based batches are preferred for a topic, for the following reasons:
- They generate uniformly sized objects (no small objects or file issues)
- They provide the least latency for high-throughput pipelines—latency is inversely proportional to inbound message rate
- They offer high efficiency because packing is maximized
The following can cause latency in MemQ:
- Time to accumulate a batch
- Time-based batch duration
- Upload latency of Amazon S3
Conclusion
MemQ, leveraging Amazon S3, provides a low-cost, cloud-native approach to creating a pub/sub platform. MemQ powers the transport of all machine learning training data at Pinterest, and we’re actively researching how to expand it to other datasets and further optimize latencies. In addition to solving our pub/sub needs, native MemQ storage enabled the ability to use pub/sub data for batch processing as well.
Recently, Pinterest made MemQ available as open source software, and it is available here: https://github.com/pinterest/memq
Building MemQ would not have been possible without the unwavering support of Dave Burgess and Chunyan Wang. Also a huge thanks to Ping-Min Lin, who has been a key driver of bug fixes and performance optimizations in MemQ that enabled large-scale production rollout. Lastly, thanks to Saurabh Joshi, Se Won Jang, Chen Chen, Divye Kapoor, Yiran Zhao, Shu Zhang, and the Logging team for providing incredible support during MemQ rollouts.