AWS Database Blog
Validate database objects after migrating from IBM Db2 LUW to Amazon RDS for MySQL, Amazon RDS for MariaDB, or Amazon Aurora MySQL
Migrating your database from IBM Db2 LUW to Amazon Relational Database Service (Amazon RDS) for MySQL, Amazon RDS for MariaDB, or Amazon Aurora MySQL-Compatible Edition is a complex, multistage process, which usually includes assessment, database schema conversion, data migration, functional testing, performance tuning, and many other steps spanning across the stages.
You can use AWS Schema Conversion Tool (AWS SCT) to convert your database schema into a format compatible with your target database. AWS Database Migration Service (AWS DMS) supports many of the most popular source and target database engines to help you migrate databases to AWS quickly and securely.
Schema migration with AWS SCT is a semi-automated process, so there is a chance of missing objects or key features in the target database. Therefore, schema validation is a crucial milestone that prevents missing objects during schema conversion and certifies that everything intended for migration has been migrated successfully.
In this post, we walk you through how to validate the database schema objects migrated from Db2 LUW to Amazon RDS for MySQL, Amazon RDS for MariaDB, or Aurora MySQL. A similar validation between Db2 LUW to Amazon Aurora PostgreSQL-Compatible Edition will be covered in another post.
Validating database objects
You should perform schema validation right after you successfully convert the source schema objects from Db2 LUW to their equivalent MySQL or MariaDB schema objects. To perform the validations, we first need to understand the different types of Db2 LUW database objects and their equivalent MySQL or MariaDB database object type.
The following list shows database objects that you can compare between Db2 LUW (source) and the corresponding MySQL or MariaDB database (target). We should validate these objects thoroughly to reduce issues during later stages of database migration.
- Schema
- Tables
- Views
- Primary keys
- Foreign keys
- Indexes
- Triggers
- Procedures
- Functions
In following sections, we deep dive into each of these object types and validate using their corresponding SQL queries to help us identify any missing migrated schema objects.
If you find differences for any of the schema objects, identify the reason of failure from the AWS SCT logs, convert the objects to the target database equivalent manually, and create the objects on the target database. For example, the SQL syntax to create data partition tables in Db2 LUW is different than that of MySQL or MariaDB. As a result, these tables aren’t created on the target database. You need to manually correct the SQL scripts to replace the target equivalent syntax for table partitions before running them on the target database.
The queries we use in these sections exclude system schemas in the source and target databases. We cover both summary-level as well as detail-level validations, wherever applicable. You can further modify these queries to include more scrutiny as required.
Schema
Schemas are used to represent a collection of database objects that serve a related functionality in an application or microservice. You should validate the schemas at the source and target databases using the following SQL queries.
Use the following SQL query for Db2 LUW:
The following screenshot is an example of the Db2 LUW output.

The following SQL query is for MySQL or MariaDB:
You get the following output.

Verify if the schema results match between the source and target database using the aforementioned SQL queries. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In this example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Extension packs
When you convert your database or data warehouse schema, AWS SCT may add additional schemas to your target database. These schemas implement SQL system functions of the source database that are required when writing your converted schema to your target database. These additional schemas are called extension packs.
When migrating your database from Db2 LUW to Amazon RDS for MySQL or MariaDB or Aurora MySQL, AWS SCT creates two extension packs: aws_db2_ext and aws_db2_ext_data, as shown in the following examples.
The following SQL query is for MySQL or MariaDB:
You get the following output.

You can directly deploy these extension pack schemas to the target database after verifying the native equivalent options in both the source and target databases.
Tables
AWS SCT converts source Db2 LUW tables to the equivalent MySQL or MariaDB target tables with appropriate data types and relative table definitions using the default or custom mapping rules. The following scripts return the counts and detail-level information for all the tables, assuming the source database doesn’t have any partitioned tables.
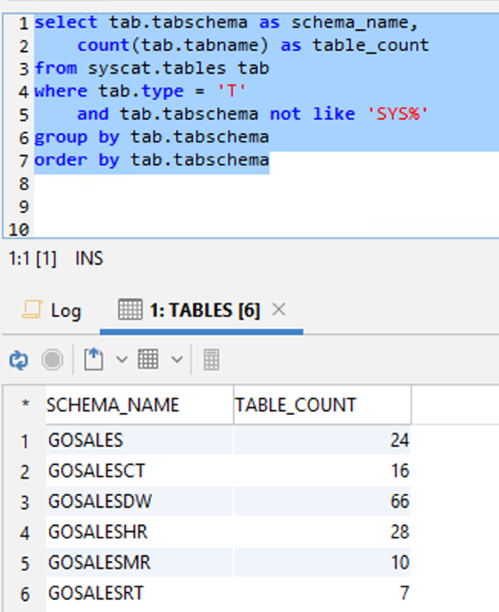
Use the following Db2 LUW query:
The following screenshot shows your output.
Use the following SQL query for MySQL or MariaDB:
You get the following output.
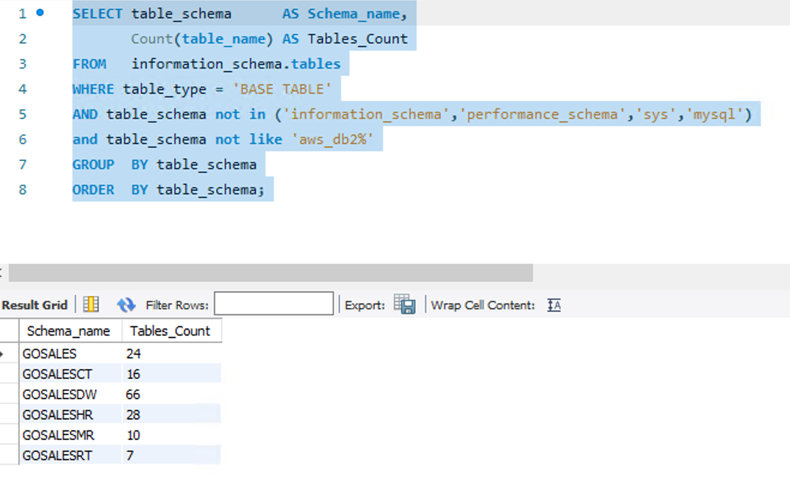
Verify the table counts between the source and target database using the aforementioned SQL queries. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In the preceding example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Views
A view is a virtual table created by a query joining one or more tables. You can validate the views count converted by AWS SCT by using the following queries on the source and target databases.
Use the following SQL query for Db2 LUW:
You get the following output.

Use the following SQL query for MySQL or MariaDB:
The following screenshot shows the output.

Verify the view counts between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In this example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Primary keys
A primary key is a column or group of columns whose values uniquely identify every row in the table. The following queries help you extract the counts and details of primary keys in source and target databases.
The following is SQL query for Db2 LUW:
The following screenshot shows the output.

Use the following SQL query for MySQL or MariaDB:
You get the following output.

To verify details including the column names in the constraint along with their ordinal position, you can use the following queries.
Use the following SQL query for Db2 LUW:
You get the following output.

The following is SQL query for MySQL or MariaDB:
The following screenshot shows the output.
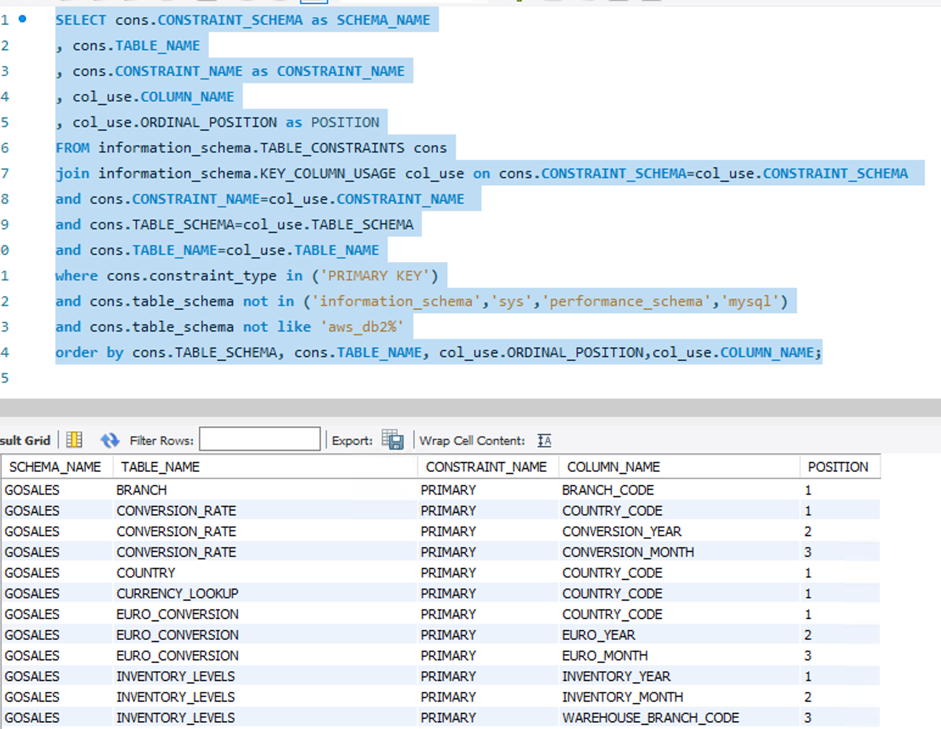
Verify the count and details of the primary keys between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In the preceding example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Foreign keys
Foreign keys link data in a parent table to the data in another child table. Foreign key constraints help maintain referential integrity between tables. You can use the following queries to get the counts and detail-level information about the foreign keys in both the source and target databases.
Use the following Db2 LUW query:
You get the following output.

Use the following MySQL or MariaDB query:
You get the following output.

For detailed information, use the following queries.
The following SQL query is for Db2 LUW:
The following screenshot shows the output.
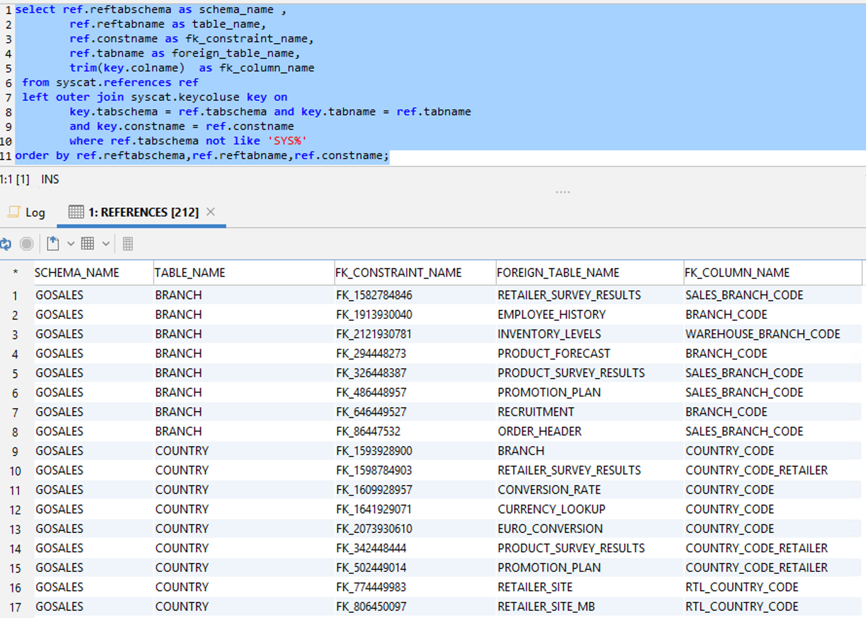
The following SQL query is for MySQL or MariaDB:
You get the following output.

Verify the count and the details of foreign keys between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In the preceding example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Indexes
Indexes play a key role in improving query performance. Because tuning methodologies differ from database to database, the number of indexes and their types vary between Db2 LUW and MySQL or MariaDB databases.
With the following queries, you can get the counts of indexes and their types in both Db2 LUW and MySQL or MariaDB databases.
Unique indexes
For unique indexes, use the following Db2 LUW query:
The following screenshot shows the output.

Use the following SQL query for MySQL or MariaDB:
You get the following output.

For detailed information, use the following queries.
The following SQL query is for Db2 LUW:
You get the following output.
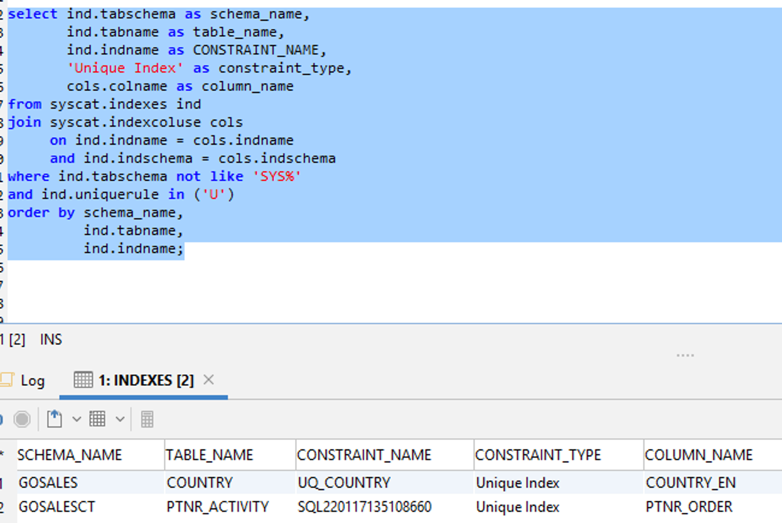
Use the following SQL query for MySQL or MariaDB:
The following screenshot shows the output.

Non-unique indexes
MySQL and MariaDB create implicit indexes on foreign keys and referenced keys so that foreign key checks can be fast and not require a table scan. The MySQL and MariaDB database queries used in this section exclude such indexes so that you can perform the validations against the source without any mismatch.
Use the following SQL query for Db2 LUW:
The output is as follows.

Use the following SQL query for MySQL or MariaDB:
You get the following output.

For detailed information, use the following queries.
The following SQL query is for Db2 LUW:
The following screenshot shows the output.

Use the following SQL query for MySQL or MariaDB:
The output is as follows.
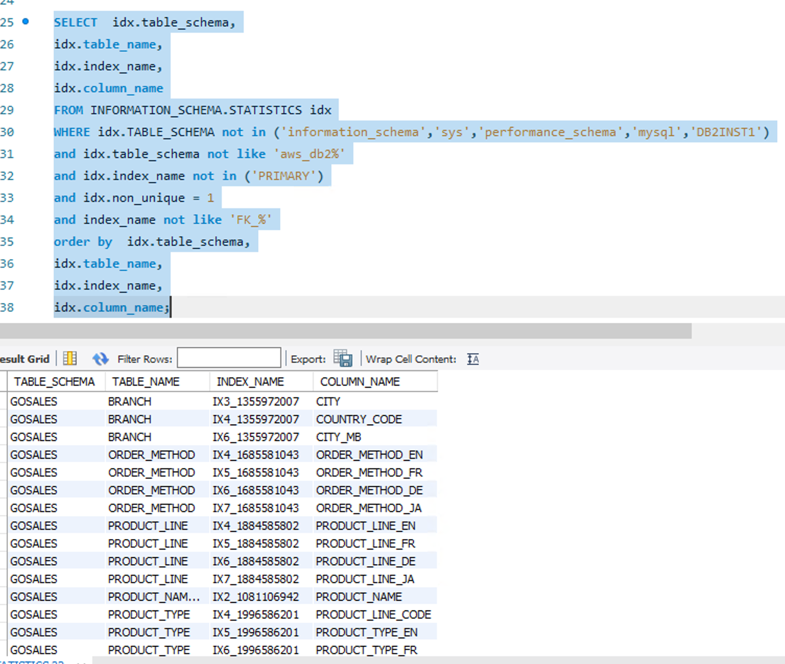
Verify the count and the details of the indexes between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In this example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Triggers
Triggers define a set of actions that are performed in response to an insert, update, or delete operation on a specified table. The following queries give you the count and details of triggers for both the source and target databases.
Use the following Db2 LUW query:
You get the following output.
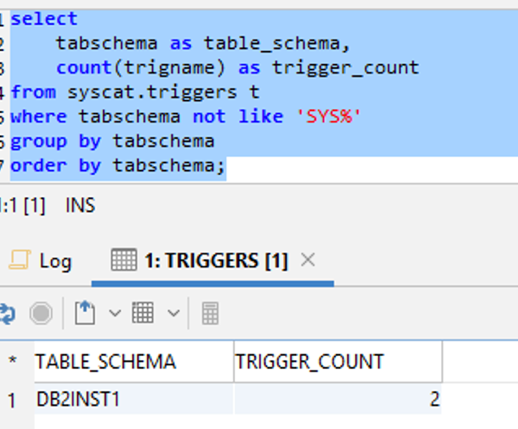
Use the following MySQL or MariaDB query:
The output is as follows.

For detail-level information, use the following queries.
The following SQL query is for Db2 LUW:
You get the following output.
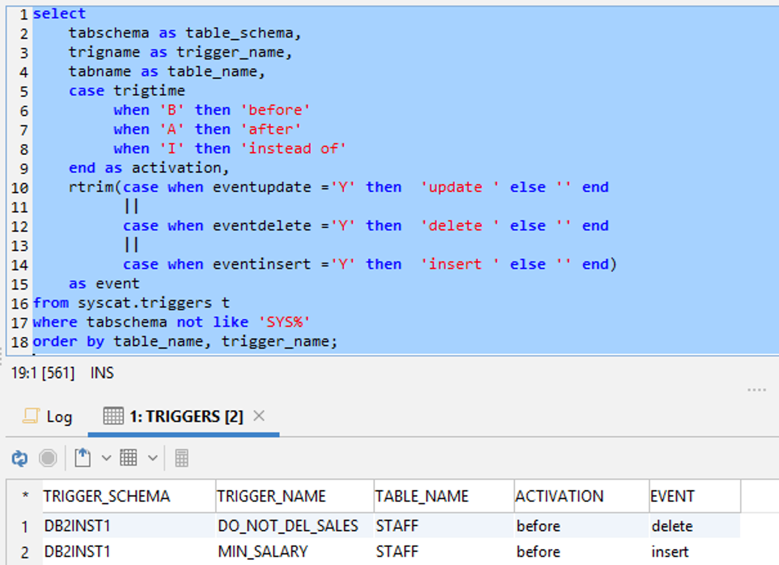
Use the following MySQL or MariaDB query:
The following screenshot shows the output.

Verify the trigger count and details between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In the preceding example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Procedures
A stored procedure is a collection of precompiled SQL statements stored in a database that can be called from an application program. Stored procedures have better performance compared to inline queries because the SQL queries are precompiled with reusable execution plans. It also improves productivity because similar SQL statements or the business logic are consolidated and reused across applications or other programs. The following queries give you the count and details of stored procedures for both the source and target databases.
The following is SQL query for Db2 LUW:
You get the following output.

Use the following SQL query for MySQL or MariaDB:
The output is as follows.

For detail-level information, use the following queries.
The following is SQL query for Db2 LUW:
You get the following output.
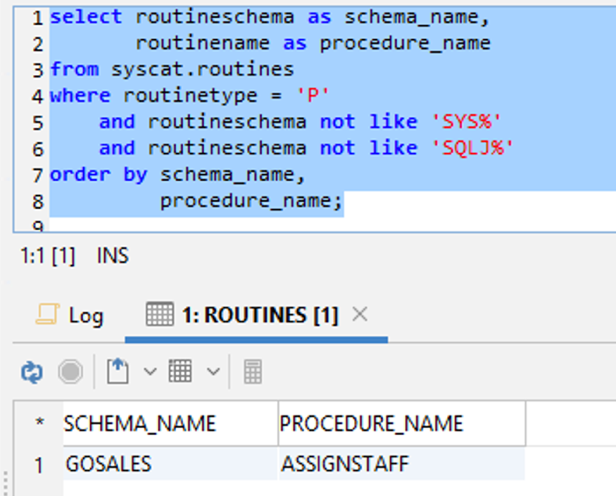
Use the following SQL query for MySQL or MariaDB:
The following screenshot shows the output.

Verify the count and the details of procedures between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In this example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Functions
Functions implement specific business or functional logic based on the given input and return a predefined output. The following queries give you the count and details of functions for both the source and target databases.
Use the following SQL query for Db2 LUW:
The following screenshot shows the output.

The following is SQL query for MySQL or MariaDB:
You get the following output.

For detail-level information, use the following queries.
Use the following SQL query for Db2 LUW:
The output is as follows.
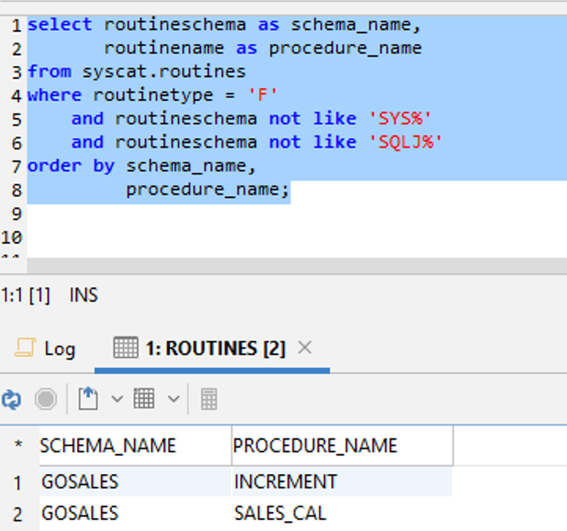
Use the following SQL query for MySQL or MariaDB:
The following screenshot shows the output.

Verify the count and the details of functions between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In the preceding example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Validating data-partitioned tables
Partitioned tables use a data organization scheme in which table data is divided across multiple storage objects, called data partitions or ranges, according to values in one or more table partitioning key columns of the table. You can use the following queries to compare the partitioned tables between the source and target.
The following is SQL query for Db2 LUW:
You get the following output.
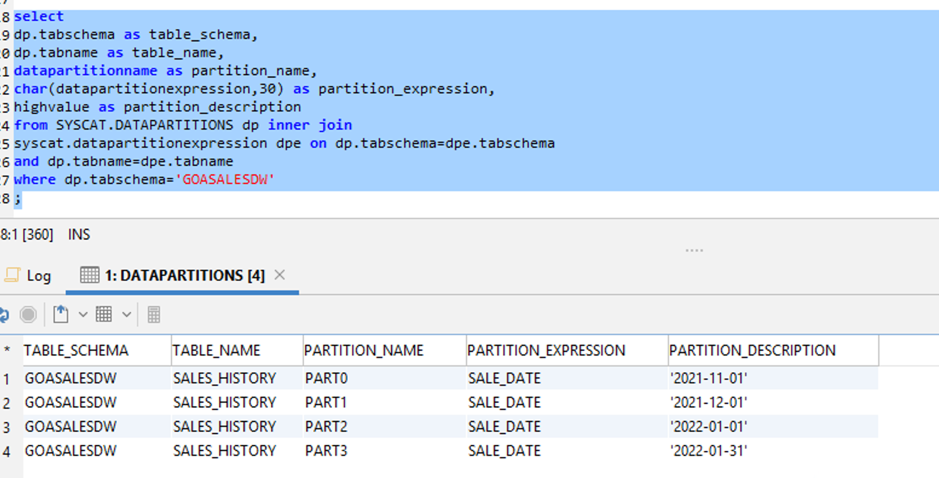
The following SQL query is for MySQL or MariaDB:
The output is as follows.

Verify the count and the details of partitioned data tables between the source and target database. If any differences are found, identify the cause of failure from the deployment logs and fix them accordingly. In the preceding example, the output is as expected. No issues were detected, so you can move to the next level of validation.
Useful MySQL or MariaDB catalog tables
The following table summarizes some of the Db2 LUW objects and their corresponding objects on MySQL and MariaDB that are helpful for database object validation. For MySQL databases with many objects and concurrent workloads, the queries provided in this post can take longer duration to complete. This can be improved to some extent using data dictionary changes in MySQL 8.0.
| Db2 LUW | MySQL or MariaDB |
| syscat.tables/ syscat.columns | information_schema.tables |
| syscat.tables/ syscat.columns | information_schema.views |
| syscat.tables/ syscat.tabconst / syscat.references / syscat.keycoluse | information_schema.TABLE_CONSTRAINTS |
| syscat.routines | information_schema.ROUTINES |
| syscat.triggers | information_schema.triggers |
| syscat.datapartitions / datapartitionexpression | Information_schema.partitions |
Handling objects not supported in MySQL or MariaDB
For the Db2 LUW objects not supported by MySQL or MariaDB (like aliases, sequences, or materialized query tables), you must perform the migration from source to target database manually to achieve the functionality that exists in the source database. You can use the queries provided in this post to iteratively validate the migrated objects to identify gaps and fix them.
Conclusion
Database object validation is an essential step that provides an in-depth view of the migration accuracy. It confirms whether all the database objects are migrated appropriately and the integrity of target database. It ensures business continuity of the dependent application processes.
In this post, we discussed post-migration validation of database objects with the metadata queries for a Db2 LUW source and Amazon RDS for MySQL, Amazon RDS for MariaDB, or Aurora MySQL target database. You can run the queries provided in this post on your source and target database to retrieve the metadata and compare the output to confirm if your migration was successful.
Let us know if you have any comments or questions. We value your feedback!
About the Authors
 Sai Parthasaradhi is a Database Migration Specialist with AWS Professional Services. He works closely with customers to help them migrate and modernize their databases on AWS.
Sai Parthasaradhi is a Database Migration Specialist with AWS Professional Services. He works closely with customers to help them migrate and modernize their databases on AWS.
 Vikas Gupta is a Lead Database Migration Consultant with AWS Professional Services. He loves to automate manual processes and enhance the user experience. He helps customers migrate and modernize workloads in the AWS Cloud, with a special focus on modern application architectures and development best practices.
Vikas Gupta is a Lead Database Migration Consultant with AWS Professional Services. He loves to automate manual processes and enhance the user experience. He helps customers migrate and modernize workloads in the AWS Cloud, with a special focus on modern application architectures and development best practices.