AWS Database Blog
Modernize database stored procedures to use Amazon Aurora PostgreSQL federated queries, pg_cron, and AWS Lambda
As part of migrating and modernizing your databases, you may continue to use your stored procedures and scheduling jobs that consolidate data from remote instances into your centralized data store. AWS Schema Conversion Tool (AWS SCT) helps you convert your legacy Oracle and SQL Server functions to their open-source equivalent. But how do you continue to use your stored procedures to extract data from remote databases? How about your existing cron jobs? How do you handle errors in the stored procedures and notify the database administrators? The PostgreSQL Extensions such as postgres_fdw, pg_cron, and aws_lambda allow you to do just that.
In this post, we demonstrate a pattern which allows you to modernize your database and refactor your existing code. We use Amazon Aurora PostgreSQL-Compatible Edition database instance to illustrate this pattern.
There is no one size fits all approach to modernizing your databases. You need to carefully plan your transformation journey with clear goals and outcomes. If handling some of your logic in the database layer suits your business needs, you may consider the approach presented in this post. Refer to Migrating Oracle databases to the AWS Cloud and Migrating Microsoft SQL Server databases to the AWS Cloud for additional guidance.
PostgreSQL Extensions
Before we begin, let’s go through the PostgreSQL extensions used in our solution.
postgres_fdw is a foreign data wrapper used to access data in remote PostgreSQL servers. Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Aurora PostgreSQL support this extension. With postgres_fdw, you can implement a federated query to retrieve data from a remote PostgreSQL database instance, store it in a centralized database, or generate reports.
AWS Lambda runs code in highly available compute infrastructure without provisioning or managing servers and operating system maintenance. The code in Lambda is organized as a function and supports many programming languages, such as Python, Node.js, Java, and Ruby. The aws_lambda extension provides the ability to invoke Lambda functions from Aurora PostgreSQL. This extension also requires the aws_commons extension, which provides helper functions to aws_lambda and many other Aurora extensions for PostgreSQL. If an error occurs in a stored procedure, you can send the error message to a Lambda function and send a notification to the DBAs using Amazon Simple Notification Service (Amazon SNS).
You can use pg_cron to schedule SQL commands and it uses the same syntax as standard CRON expression. We can schedule the stored procedures and automate routine maintenance tasks using this extension.
Solution overview
The source database consists of the tables and data that we want to retrieve and load into the reporting database. The pg_cron extension runs the stored procedure according to a predefined schedule. The stored procedure copies the data based on the predefined business logic. If any errors are encountered, it invokes a Lambda function to send out the error notification to users subscribed to an SNS topic. The following diagram illustrates the solution architecture and flow.

In this post, we walk you through the steps to create resources with AWS CloudFormation, configure your stored procedures, and test the solution.
Prerequisites
Make sure you complete the following prerequisite steps:
- Set up the AWS Command Line Interface (AWS CLI) to run commands for interacting with your AWS resources.
- Have the appropriate permissions to interact with resources in your AWS account.
Create resources with AWS CloudFormation
The CloudFormation template for this solution deploys the following key resources:
- Two Aurora PostgreSQL clusters for the source and reporting databases, containing database tables and stored procedures
- A Lambda function to relay the error message to Amazon SNS
- An SNS topic for email notification
- An AWS Cloud9 instance to connect to the databases for setup and testing.
Use the AWS Pricing Calculator to estimate the cost before you run this solution. The resources deployed are not eligible for the Free Tier, but if you choose the stack defaults, you should incur costs less than $3.00, assuming that you clean up the stack in an hour.
To create the resources, complete the following steps:
- Clone the GitHub project by running the following commands from your terminal:
- Deploy AWS CloudFormation resources with the following code. Replace
youreamil@example.comwith a valid email address.Provisioning the resources takes approximately 15–20 minutes to complete. You can ensure successful stack deployment by going to the AWS CloudFormation console and verifying that the status shows as
CREATE_COMPLETE.

While the stack is being created, you receive an email to confirm an SNS subscription. - Choose Confirm subscription in your email.


A browser window opens with your subscription confirmation.
Configure your stored procedures
To configure your stored procedures, complete the following steps:
- On the AWS Cloud9 console, under Your environments, choose the environment
PostgreSQLInstance. - Choose Open IDE.
This opens an IDE, which you use to configure, deploy, and test your stored procedure. - In your Cloud9 terminal, run the following commands to clone the repository and install the required tools:
The script takes 5 minutes to install all the necessary tools. Make sure that the installation is complete before you move to the next step.

- Run the following command to initialize environment variables:
- Create the source and reporting database objects by running the following shell script command:
This script creates
employeeanddepartmenttables and inserts a few sample records in the source database.After the script creates the database objects in the source database, it creates an
employeetable andemployee_sp,error_handler_sp, andschedule_sp_jobstored procedures in thereportingdatabase. As a final step, it creates thepostgres_fdwextension, a foreign server, a user mapping, and foreign tables to pull the data from the source database. To learn more aboutpostgres_fdw, refer to the PostgreSQL documentation. - Observe the tables and schema in the source database by running the following commands one by one:

Theemployeetable stores the raw data, which may contain null and duplicate values. Thedepartmenttable serves as a lookup table for department names. - Exit from the source database using the following command:
- Observe the stored procedures and table in the reporting database by running the following commands one by one:
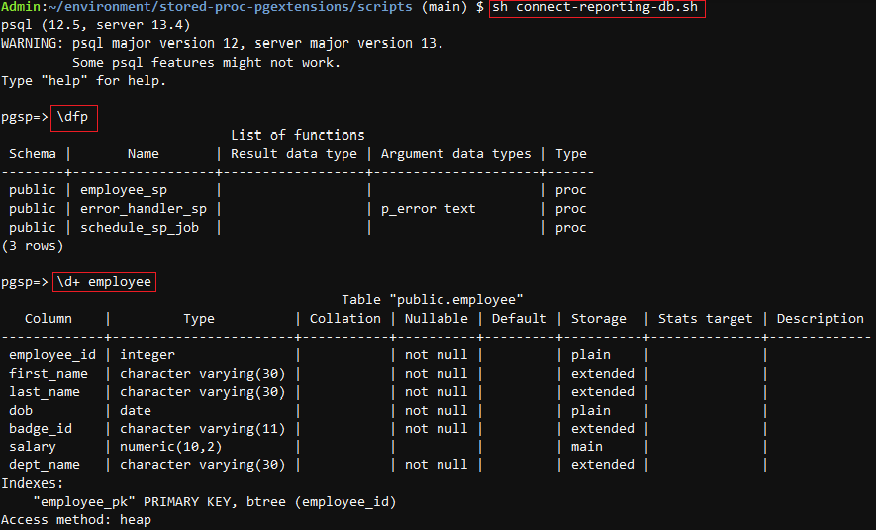
Theemployee_spstored procedure validates and copies the raw data from the employee source table to the employee table in the reporting database.error_handler_sphandles errors and sends out a notification to the registered email address.schedule_sp_jobautomatically schedules the run of theemployee_spprocedure by creating a cron job. - Exit from the database using the following command:


Test the stored procedures
After we create all the required tables and stored procedures, we’re ready to test the solution. Run the following shell script:
This invokes the employee_sp stored procedure in the reporting database. It validates and copies the employee and department data from the source database to the employee table in the reporting database using the following code:
Verify the inserted records in the employee table of the reporting database by running the following commands one by one:

Exit from the database using the following command:
Test error notifications
The source table may contain duplicate records, and we don’t want to insert duplicate records into the reporting database. You can verify that the stored procedure throws an error and sends an email notification when an attempt is made to insert a duplicate record into the employee table of the reporting database.
We simulate an error scenario by running the following shell script:
The script inserts a duplicate record in the employee table of the source database and runs execute_sp.sh to invoke the employee_sp() stored procedure to copy the data from the source database to the remote database.
A primary key violation occurs when a duplicate record is inserted into the reporting database. This exception gets caught in the exception block, and the error_handler_sp stored procedure gets invoked. See the following code:
When the error_handler_sp stored procedure is invoked, it creates the aws_lambda extension if it doesn’t exist. Then it passes the error message to the Lambda function ExceptionLambda, which invokes the function.
The Lambda function publishes the error message to the SNS topic. You receive an email with the subject “Stored Procedure Error” to notify you of the exception when attempting to insert duplicate records.
Schedule your stored procedure
In the production environment, you may want to schedule your stored procedure to run in an automated manner.
- Run the following shell script to schedule running the stored procedure:
The script refreshes the database objects for testing and invokes the
schedule_sp_jobstored procedure.schedule_sp_jobcreates thepg_cronextension if it doesn’t exist, and schedules a cron job that runs theemployee_spstored procedure every 10 minutes. - Run the following SQL query in the reporting database to confirm the creation of cron job. We use the cron expression
*/10 * * * *to allow the job to run every 10 minutes. - You can review the status of the scheduled job using the following SQL query:
After 10 minutes, the cleansed data gets populated in the
employeetable of the reporting database. - Now you can unschedule the cron job by running the following SQL command:
With pg_cron, you can schedule the execution of the SQL commands periodically to perform recurring tasks.
Clean up
To avoid incurring ongoing charges, clean up your infrastructure by deleting the AmazonAuroraPostgreSQLStoredProc stack from the AWS CloudFormation console. Delete any other resources you may have created as a prerequisite for this exercise.
Conclusion
In this post, we demonstrated how to modernize your stored procedures using Aurora PostgreSQL extensions such as postgres_fdw, pg_cron, and aws_lambda. Aurora PostgreSQL extensions enhance the database development experience by providing equivalent functionality to commercial databases. Carefully consider your business goals and outcomes when planning your modernization journey.
For more information about Aurora extensions, refer to Working with extensions and foreign data wrappers. For information on using database triggers to enable near real-time notifications through Lambda and Amazon SNS, refer to Enable near real-time notifications from Amazon Aurora PostgreSQL by using database triggers, AWS Lambda, and Amazon SNS.
Let us know how this post helped with your database modernization journey.
About the Authors
 Prathap Thoguru is an Enterprise Solutions Architect at Amazon Web Services. He has 15 plus years of experience in the I.T. industry and he is a 9 x AWS certified professional. He helps customers in migrating their on-premises workloads to AWS Cloud.
Prathap Thoguru is an Enterprise Solutions Architect at Amazon Web Services. He has 15 plus years of experience in the I.T. industry and he is a 9 x AWS certified professional. He helps customers in migrating their on-premises workloads to AWS Cloud.
 Kishore Dhamodaran is a Senior Solutions Architect with Amazon Web Services. Kishore helps customers with their cloud enterprise strategy and migration journey, leveraging his years of industry and cloud experience.
Kishore Dhamodaran is a Senior Solutions Architect with Amazon Web Services. Kishore helps customers with their cloud enterprise strategy and migration journey, leveraging his years of industry and cloud experience.