AWS Database Blog
Support JSON data using Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL and Java Spring Boot on AWS
Many customers choose Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition to store JSON business objects along with relational transactional data. You can also use the Spring Boot Java framework to implement microservice applications. The Spring Boot framework provides rich features, including auto configuration, dependency injection, metrics measurement, health checks, and more, which expedite application development.
JSON is a common data exchange format used in REST APIs, web applications, and mobile applications. Unlike a flat relational structure, JSON supports a hierarchical structure of basic types, nested objects, and nested arrays. It’s widely used in schema-less document databases which allow documents to evolve with application’s needs.
In this post, we walk you through how to support business data captured in JSON format in microservices developed in the Spring Boot Java framework, Amazon RDS for PostgreSQL, or Aurora PostgreSQL.
Overview of solution
PostgreSQL provides robust features to support JSON business data through the jsonb data types. This post uses Amazon RDS for PostgreSQL to show how you can create a database schema to store JSON business objects. We cover how you can implement a data access layer using the Spring Data Java Persistence API (JPA) to access JSON data in the Amazon RDS for PostgreSQL tables. We also explain how you can create microservices to save and query JSON data. Finally, we show how you can create indexes to improve the performance of searching business data using JSON keys. You can apply the same approach to the case of using Aurora PostgreSQL to store your JSON business objects. The post Is Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL a better choice for me? analyzes the architectural differences between Amazon RDS for PostgreSQL and Aurora PostgreSQL and helps you select the best option.
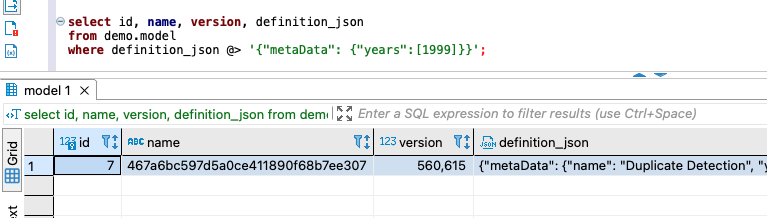
We use the following JSON sample data to explain our solution:
The sample JSON describes a data processing pipeline that ingests data records based on the start date and end date in the inputParameters structure, and then detects duplicate records using a machine learning model specified in the container data element. You can create many different data processing pipeline jobs based on the same model but with different start and end dates.
The process includes the following steps:
- Create a table to store the sample pipeline definition.
- Configure the Spring Boot application to support PostgreSQL and JSON data types.
- Create Spring Profiles to connect to a PostgreSQL database on AWS.
- Create database access classes and a Spring Boot service bean to save and query sample JSON business data.
- Create REST APIs to save and retrieve JSON data.
- Test the REST APIs.
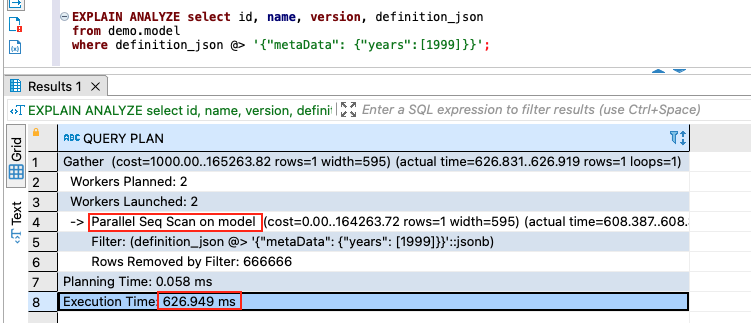
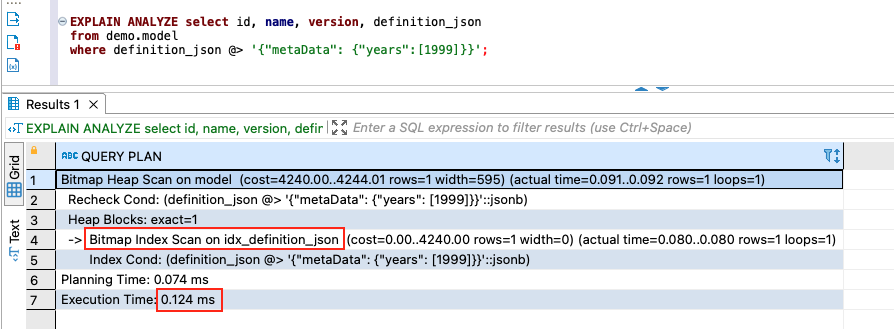
- Create an index to improve query performance.
Prerequisites
You should have some experience with Spring Boot applications, the Spring RESTful web service, Spring Data Java Persistence, and relational databases. You should also have a basic understanding of the JSON data format. To follow the examples in this post, you need to create your own Spring Boot based project by visiting Spring Initializr.
Create a table to store the pipeline definition
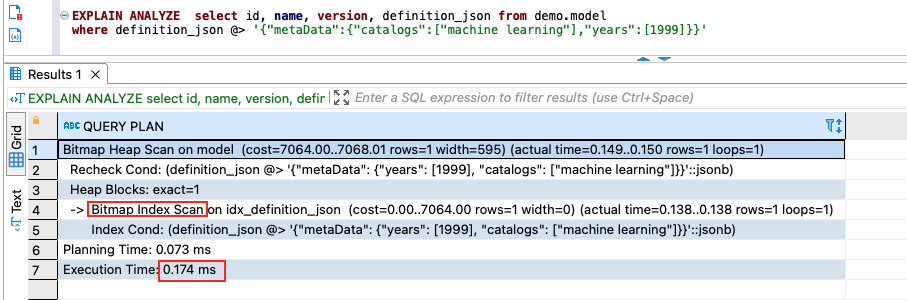
PostgreSQL offers two data types for storing JSON data: The json and jsonb data types accept almost the same sets of values as input. The json data type stores the input JSON string as text, and no preprocessing is needed to save the string into a database column. On the other hand, when the jsonb data type is used to save an input text, the input text is converted into a decomposed binary format. The jsonb data type supports indexing, which offers a significant performance advantage over the json data type on read operations. The jsonb data type has more functions and operators to use than the json data type.
In the following SQL, we use the jsonb data type to create a table to store the sample pipeline definition. The table contains the following columns:
- id – A primary key
- name – A text string for the pipeline name
- version – An integer for the pipeline version
- definition_json – A jsonb data field to save the pipeline definition
See the following code: