AWS Big Data Blog
Use Karpenter to speed up Amazon EMR on EKS autoscaling
Amazon EMR on Amazon EKS is a deployment option for Amazon EMR that allows organizations to run Apache Spark on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, the Spark jobs run on the Amazon EMR runtime for Apache Spark. This increases the performance of your Spark jobs so that they run faster and cost less than open source Apache Spark. Also, you can run Amazon EMR-based Apache Spark applications with other types of applications on the same EKS cluster to improve resource utilization and simplify infrastructure management.
Karpenter was introduced at AWS re:Invent 2021 to provide a dynamic, high performance, open-source cluster auto scaling solution for Kubernetes. It automatically provisions new nodes in response to unschedulable pods. It observes the aggregate resource requests of unscheduled pods and makes decisions to launch new nodes and terminate stop them to reduce scheduling latencies as well as infrastructure costs.
To configure Karpenter, you create provisioners that define how Karpenter manages the pods that are pending and expires nodes. Although most use cases are addressed with a single provisioner, multiple provisioners are useful in multi-tenant use cases such as isolating nodes for billing, using different node constraints (such as no GPUs for a team), or using different deprovisioning settings. Karpenter launches nodes with minimal compute resources to fit un-schedulable pods for efficient binpacking. It works in tandem with the Kubernetes scheduler to bind un-schedulable pods to the new nodes that are provisioned. The following diagram illustrates how it works.
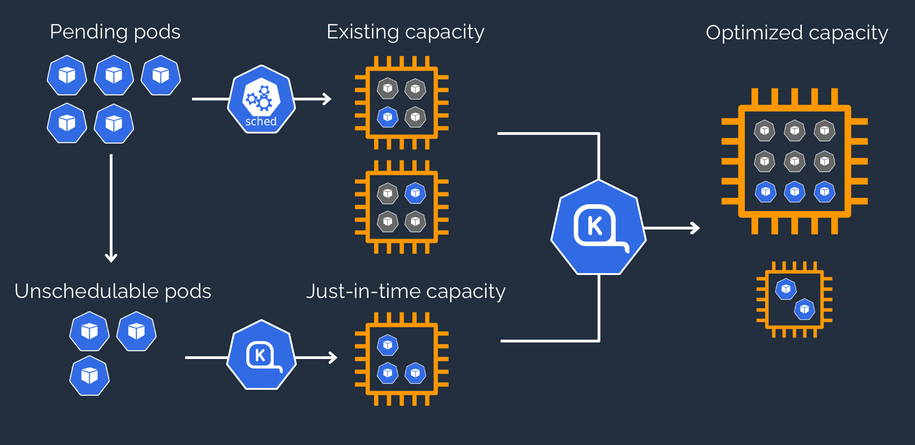
This post shows how to integrate Karpenter into your EMR on EKS architecture to achieve faster and capacity-aware auto scaling capabilities to speed up your big data and machine learning (ML) workloads while reducing costs. We run the same workload using both Cluster Autoscaler and Karpenter, to see some of the improvements we discuss in the next section.
Improvements compared to Cluster Autoscaler
Like Karpenter, Kubernetes Cluster Autoscaler (CAS) is designed to add nodes when requests come in to run pods that can’t be met by current capacity. Cluster Autoscaler is part of the Kubernetes project, with implementations by major Kubernetes cloud providers. By taking a fresh look at provisioning, Karpenter offers the following improvements:
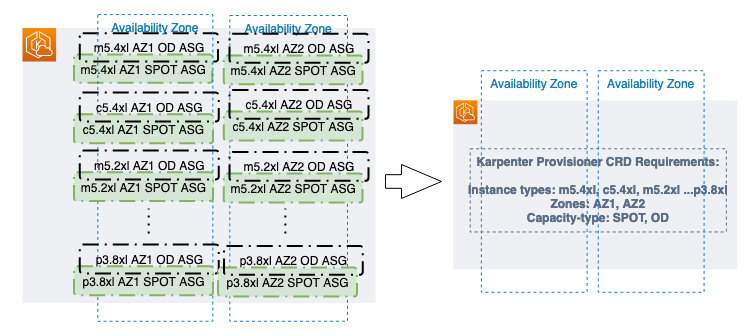
- No node group management overhead – Because you have different resource requirements for different Spark workloads along with other workloads in your EKS cluster, you need to create separate node groups that can meet your requirements, like instance sizes, Availability Zones, and purchase options. This can quickly grow to tens and hundreds of node groups, which adds additional management overhead. Karpenter manages each instance directly, without the use of additional orchestration mechanisms like node groups, taking a group-less approach by calling the EC2 Fleet API directly to provision nodes. This allows Karpenter to use diverse instance types, Availability Zones, and purchase options by simply creating a single provisioner, as shown in the following figure.
- Quick retries – If the Amazon Elastic Compute Cloud (Amazon EC2) capacity isn’t available, Karpenter can retry in milliseconds instead of minutes. This is can be a really useful if you’re using EC2 Spot Instances and you’re unable to get capacity to specific instance types.
- Designed to handle full flexibility of the cloud – Karpenter has the ability to efficiently address the full range of instance types available through AWS. Cluster Autoscaler wasn’t originally built with the flexibility to handle hundreds of instance types, Availability Zones, and purchase options. We recommend being as flexible as you can be to enable Karpenter get the just-in-time capacity you need.
- Improves the overall node utilization by binpacking – Karpenter batches pending pods and then binpacks them based on CPU, memory, and GPUs required, taking into account node overhead (for example, daemon set resources required). After the pods are binpacked on the most efficient instance type, Karpenter takes other instance types that are similar or larger than the most efficient packing, and passes the instance type options to an API called EC2 Fleet, following some of the best practices of instance diversification to improve the chances of getting the request capacity.
Best practices using Karpenter with EMR on EKS
For general best practices with Karpenter, refer to Karpenter Best Practices. The following are additional things to consider with EMR on EKS:
- Avoid inter-AZ data transfer cost by either configuring the Karpenter provisioner to launch in a single Availability Zone or use node selector or affinity and anti-affinity to schedule the driver and the executors of the same job to a single Availability Zone. See the following code:
- Cost optimize Spark workloads using EC2 Spot Instances for executors and On-Demand Instances for the driver by using the node selector with the label karpenter.sh/capacity-type in the pod templates. We recommend using pod templates to specify driver pods to run on On-Demand Instances and executor pods to run on Spot Instances. This allows you to consolidate provisioner specs because you don’t need two specs per job type. It also follows the best practice of using customization defined on workload types and to keep provisioner specs to support a broader number of use cases.
- When using EC2 Spot Instances, maximize the instance diversification in the provisioner configuration to adhere to the best practices. To select suitable instance types, you can use the ec2-instance-selector, a CLI tool and go library that recommends instance types based on resource criteria like vCPUs and memory.
Solution overview
This post provides an example of how to set up both Cluster Autoscaler and Karpenter in an EKS cluster and compare the auto scaling improvements by running a sample EMR on EKS workload.
The following diagram illustrates the architecture of this solution.
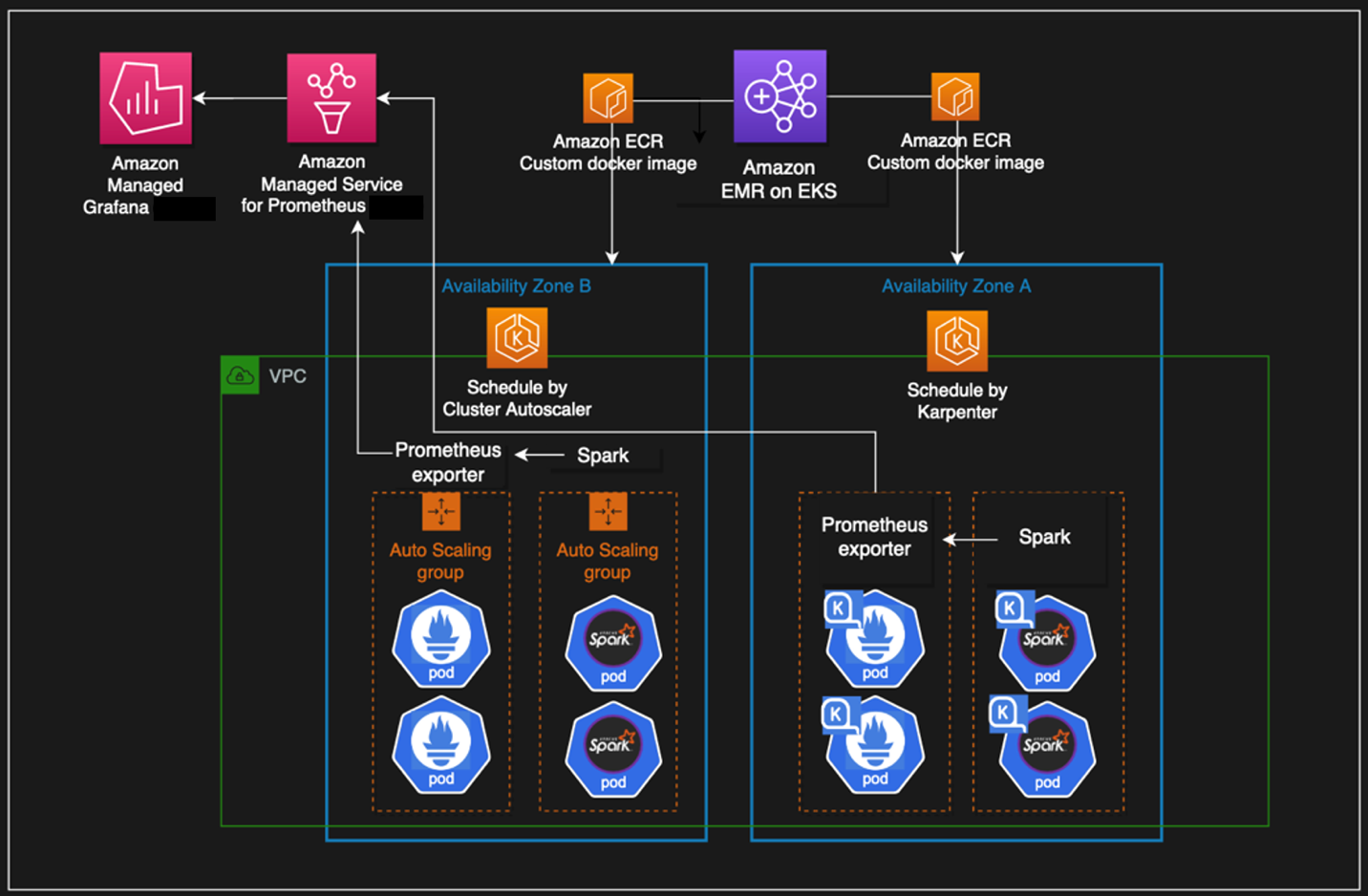
We use the Transaction Processing Performance Council-Decision Support (TPC-DS), a decision support benchmark to sequentially run three Spark SQL queries (q70-v2.4, q82-v2.4, q64-v2.4) with a fixed number of 50 executors, against 17.7 billion records, approximately 924 GB compressed data in Parquet file format. For more details on TPC-DS, refer to the eks-spark-benchmark GitHub repo.
We submit the same job with different Spark driver and executor specs to mimic different jobs solely to observe the auto scaling behavior and binpacking. We recommend you right-size your Spark executors based on the workload characteristics for production workloads.
The following code is an example Spark configuration that results in pod spec requests of 4 vCPU and 15 GB:
We use pod templates to schedule Spark drivers on On-Demand Instances and executors on EC2 Spot Instances (which can save up to 90% over On-Demand Instance prices). Spark’s inherent resiliency has the driver launch new executors to replace the ones that fail due to Spot interruptions. See the following code:
Prerequisites
We use an AWS Cloud9 IDE to run all the instructions throughout this post.
To create your IDE, run the following commands in AWS CloudShell. The default Region is us-east-1, but you can change it if needed.
Navigate to the AWS Cloud9 IDE using the URL from the output of the script.
Install tools on the AWS Cloud9 IDE
Install the following tools required on the AWS Cloud9 environment by the running a script:
Run the following instructions in your AWS Cloud9 environment and not CloudShell.
- Clone the GitHub repository:
- Set up the required environment variables. Feel free to adjust the following code according to your needs:
- Install the AWS Cloud9 CLI tools:
Provision the infrastructure
We set up the following resources using the provision infrastructure script:
- A new EKS cluster
- EMR on EKS enabler
- The required AWS Identity and Access Management (IAM) roles
- An Amazon Simple Storage Service (Amazon S3) bucket to store results and pod templates
- Karpenter set up to scale in Availability Zone {AWS_REGION}a
- Optionally, Cluster Autoscaler set up to scale multiple node groups in Availability Zone {AWS_REGION}b
- Prometheus to ship metrics to Amazon Managed Service for Prometheus
- Create the EMR on EKS and Karpenter infrastructure:
- Validate the setup:
Understanding Karpenter configurations
Because the sample workload has driver and executor specs that are of different sizes, we have identified the instances from c5, c5a, c5d, c5ad, c6a, m4, m5, m5a, m5d, m5ad, and m6a families of sizes 2xlarge, 4xlarge, 8xlarge, and 9xlarge for our workload using the amazon-ec2-instance-selector CLI. With CAS, we need to create a total of 12 node groups, as shown in eksctl-config.yaml, but can define the same constraints in Karpenter with a single provisioner, as shown in the following code:
We have set up both auto scalers to scale down nodes that are empty for 30 seconds using ttlSecondsAfterEmpty in Karpenter and --scale-down-unneeded-time in CAS.
Karpenter by design will try to achieve the most efficient packing of the pods on a node based on CPU, memory, and GPUs required.
Run a sample workload
To run a sample workload, complete the following steps:
- Lets review the AWS Command Line Interface (AWS CLI) command to submit a sample job:
- Submit four jobs with different driver and executor vCPUs and memory sizes on Karpenter:
- To monitor the pods’s autoscaling status in real time, open a new terminal in Cloud9 IDE and run the following command (nothing is returned at the start):
- Observe the EC2 instance and node auto scaling status in a second terminal tab by running the following command (by design, Karpenter schedules in Availability Zone a):
Compare with Cluster Autoscaler (Optional)
We have set up Cluster Autoscaler during the infrastructure setup step with the following configuration:
- Launch EC2 nodes in Availability Zone b
- Contain 12 node groups (6 each for On-Demand and Spot)
- Scale down unneeded nodes after 30 seconds with
--scale-down-unneeded-time - Use the least-waste expander on CAS, which can select the node group that will have the least idle CPU for binpacking efficiency
- Submit four jobs with different driver and executor vCPUs and memory sizes on CAS:
- To monitor the pods’s autoscaling status in real time, open a new terminal in Cloud9 IDE and run the following command (nothing is returned at the start):
- Observe the EC2 instance and node auto scaling status in a second terminal tab by running the following command (by design, CAS schedules in Availability Zone b):
Observations
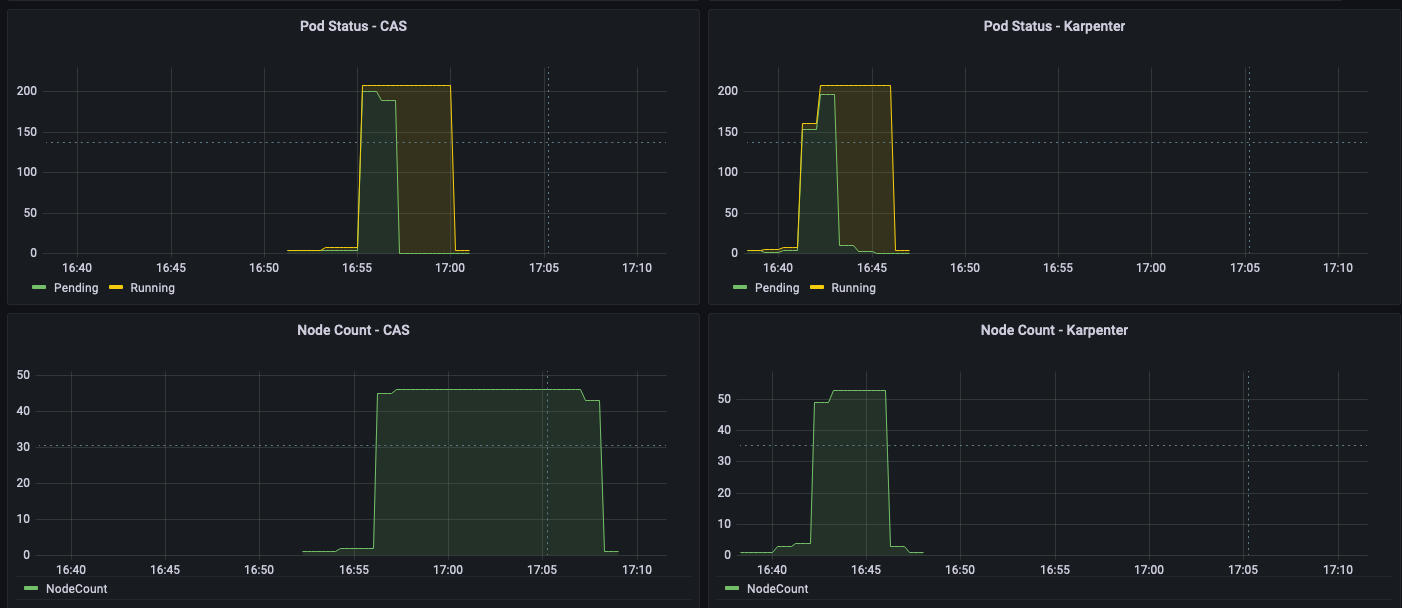
The time from pod creation to being scheduled on average is less with Karpenter than CAS, as shown in the following figure; you can see a noticeable difference when you run large scale workloads.

As shown in the following figures, as the jobs were completed, Karpenter was able to scale down the nodes that aren’t needed within seconds. In contrast, CAS takes minutes, because it sends a signal to the node groups, adding additional latency. This in turn helps reduce overall costs by reducing the number of seconds unneeded EC2 instances are running.
Clean up
To clean up your environment, delete all the resources created in reverse order by running the cleanup script:
Conclusion
In this post, we showed you how to use Karpenter to simplify EKS node provisioning, and speed up auto scaling of EMR on EKS workloads. We encourage you to try Karpenter and provide any feedback by creating a GitHub issue.
Further reading
- Concepts: Understand key concepts of Karpenter
- Karpenter Best Practices
- Migrate Kubernetes cluster autoscaler to Karpenter
- Karpenter node provisioner for Kubernetes
About the Authors
 Changbin Gong is a Principal Solutions Architect at Amazon Web Services. He engages with customers to create innovative solutions that address customer business problems and accelerate the adoption of AWS services. In his spare time, Changbin enjoys reading, running, and traveling.
Changbin Gong is a Principal Solutions Architect at Amazon Web Services. He engages with customers to create innovative solutions that address customer business problems and accelerate the adoption of AWS services. In his spare time, Changbin enjoys reading, running, and traveling.
 Sandeep Palavalasa is a Sr. Specialist Containers SA at Amazon Web Services. He is a software technology leader with over 12 years of experience in building large-scale, distributed software systems. His professional career started with a focus on monitoring and observability and he has a strong cloud architecture background. He likes working on distributed systems and is excited to talk about microservice architecture design. His current interests are in the areas of container services and serverless technologies.
Sandeep Palavalasa is a Sr. Specialist Containers SA at Amazon Web Services. He is a software technology leader with over 12 years of experience in building large-scale, distributed software systems. His professional career started with a focus on monitoring and observability and he has a strong cloud architecture background. He likes working on distributed systems and is excited to talk about microservice architecture design. His current interests are in the areas of container services and serverless technologies.