AWS Big Data Blog
Build a search application with Amazon OpenSearch Serverless
In this post, we demonstrate how to build a simple web-based search application using the recently announced Amazon OpenSearch Serverless, a serverless option for Amazon OpenSearch Service that makes it easy to run petabyte-scale search and analytics workloads without having to think about clusters. The benefit of using OpenSearch Serverless as a backend for your search application is that it automatically provisions and scales the underlying resources based on the search traffic demands, so you don’t have to worry about infrastructure management. You can simply focus on building your search application and analyzing the results. OpenSearch Serverless is powered by the open-source OpenSearch project, which consists of a search engine, and OpenSearch Dashboards, a visualization tool to analyze your search results.
Solution overview
There are many ways to build a search application. In our example, we create a simple Java script front end and call Amazon API Gateway, which triggers an AWS Lambda function upon receiving user queries. As shown in the following diagram, API Gateway acts as a broker between the front end and the OpenSearch Serverless collection. When the user queries the front-end webpage, API Gateway passes requests to the Python Lambda function, which runs the queries on the OpenSearch Serverless collection and returns the search results.

To get started with the search application, you must first upload the relevant dataset, a movie catalog in this case, to the OpenSearch collection and index them to make them searchable.
Create a collection in OpenSearch Serverless
A collection in OpenSearch Serverless is a logical grouping of one or more indexes that represent a workload. You can create a collection using the AWS Management Console or AWS Software Development Kit (AWS SDK). Follow the steps in Preview: Amazon OpenSearch Serverless – Run Search and Analytics Workloads without Managing Clusters to create and configure a collection in OpenSearch Serverless.

Create an index and ingest data
After your collection is created and active, you can upload the movie data to an index in this collection. Indexes hold documents, and each document in this example represents a movie record. Documents are comparable to rows in the database table. Each document (the movie record) consists of 10 fields that are typically searched for in a movie catalog, like the director, actor, release date, genre, title, or plot of the movie. The following is a sample movie JSON document:
For the search catalog, you can upload the sample-movies.bulk dataset sourced from the Internet Movies Database (IMDb). OpenSearch Serverless offers the same ingestion pipeline and clients to ingest the data as OpenSearch Service, such as Fluentd, Logstash, and Postman. Alternatively, you can use the OpenSearch Dashboards Dev Tools to ingest and search the data without configuring any additional pipelines. To do so, log in to OpenSearch Dashboards using your SAML credentials and choose Dev tools.
To create a new index, use the PUT command followed by the index name:
A confirmation message is displayed upon successful creation of your index.
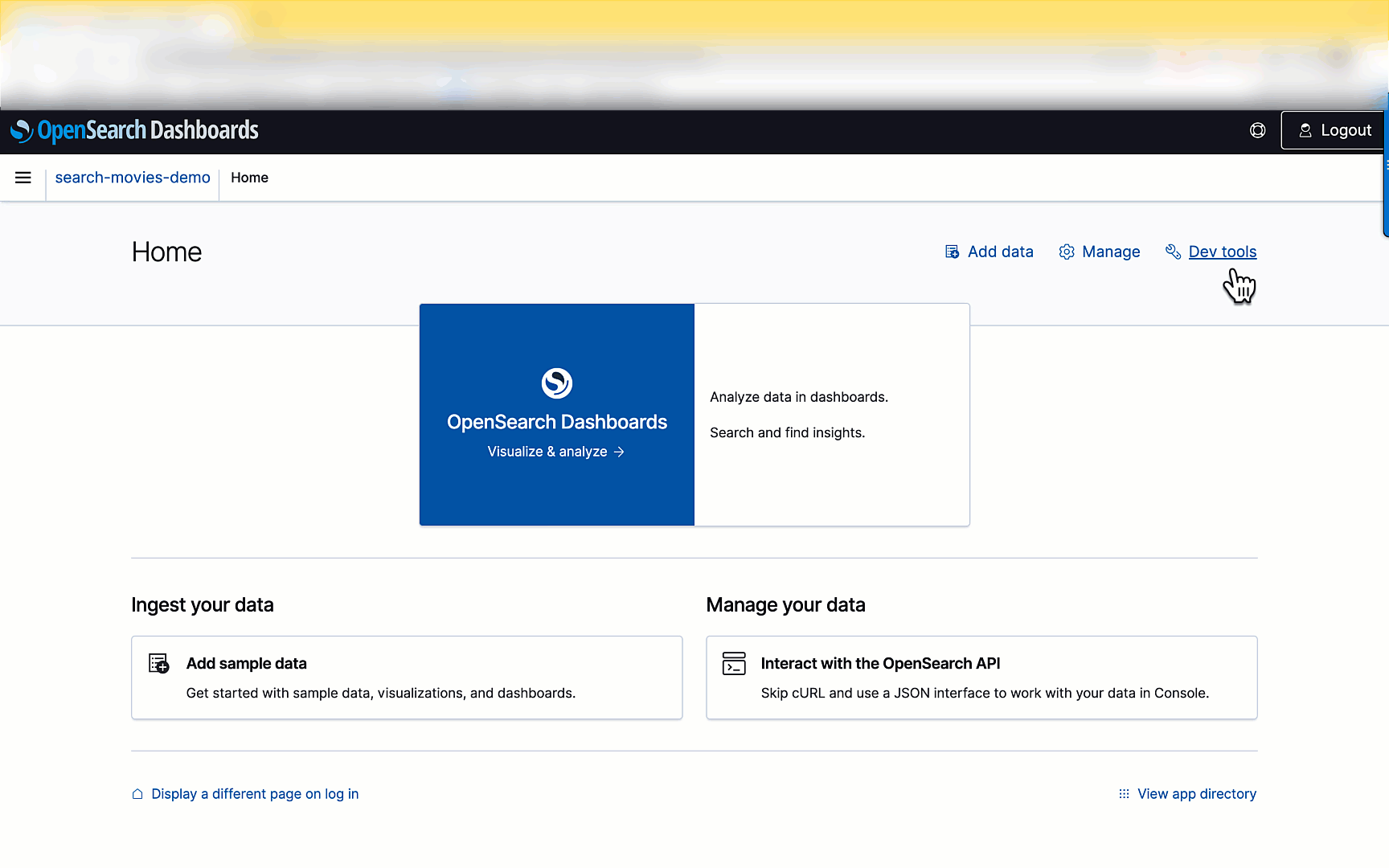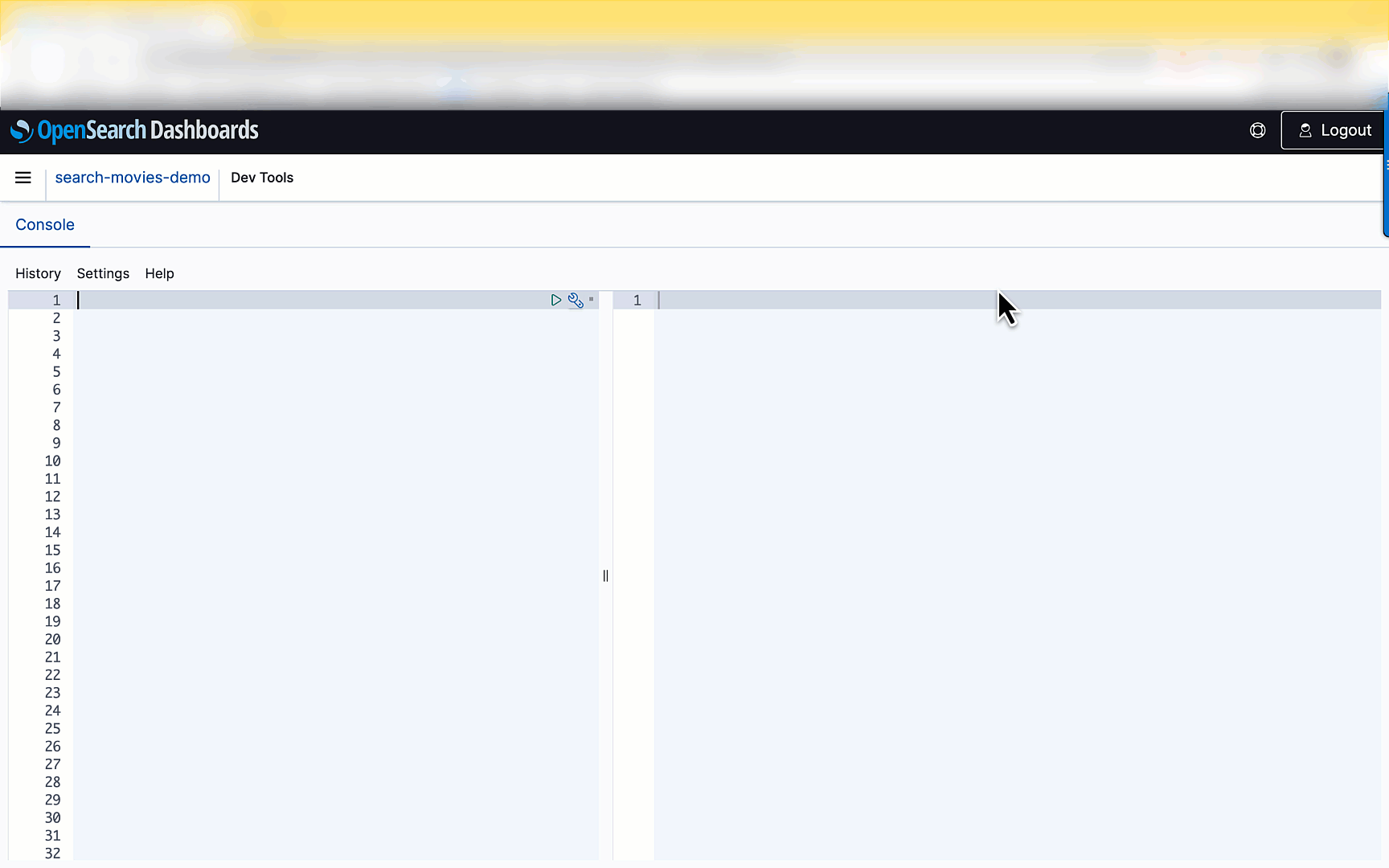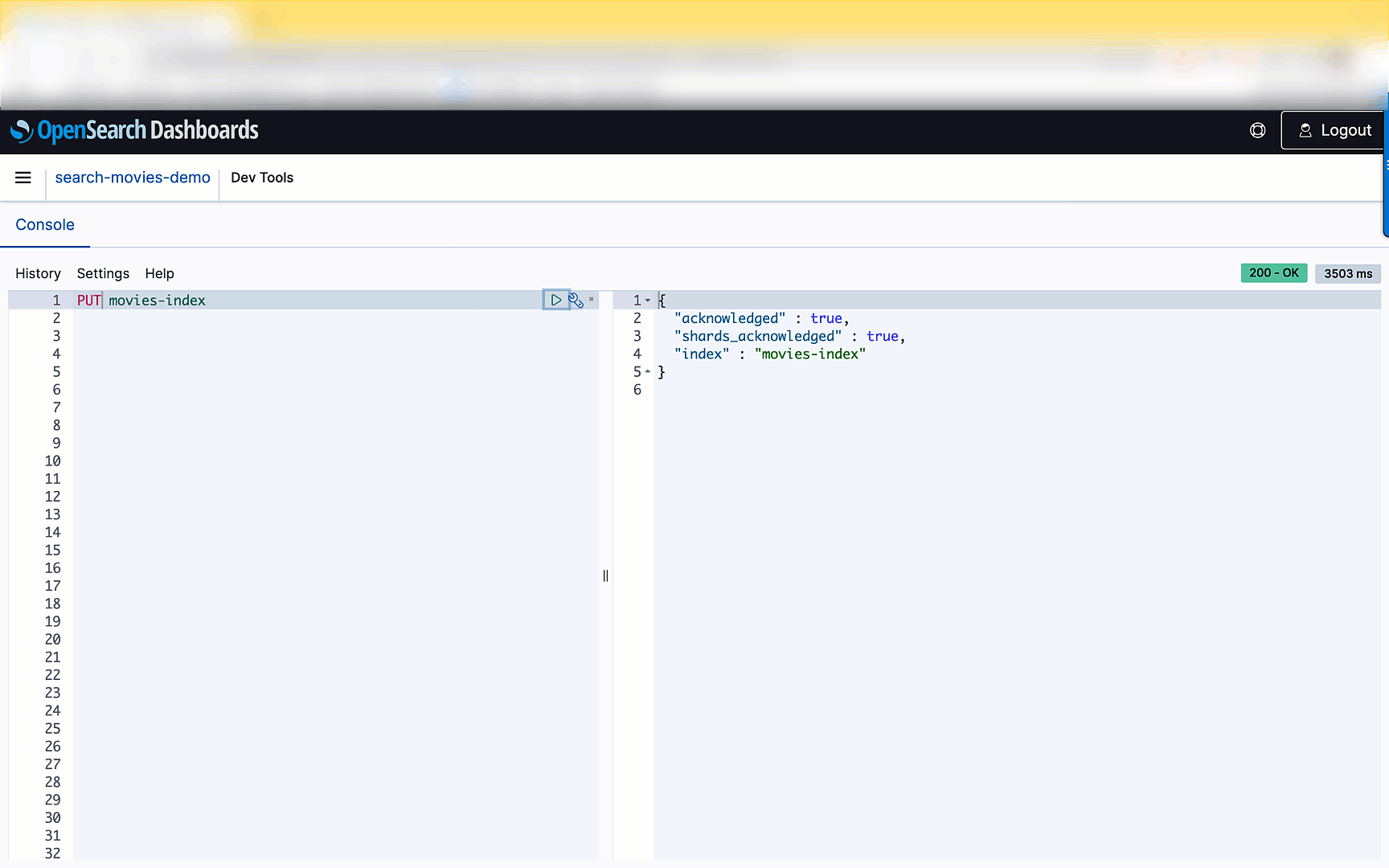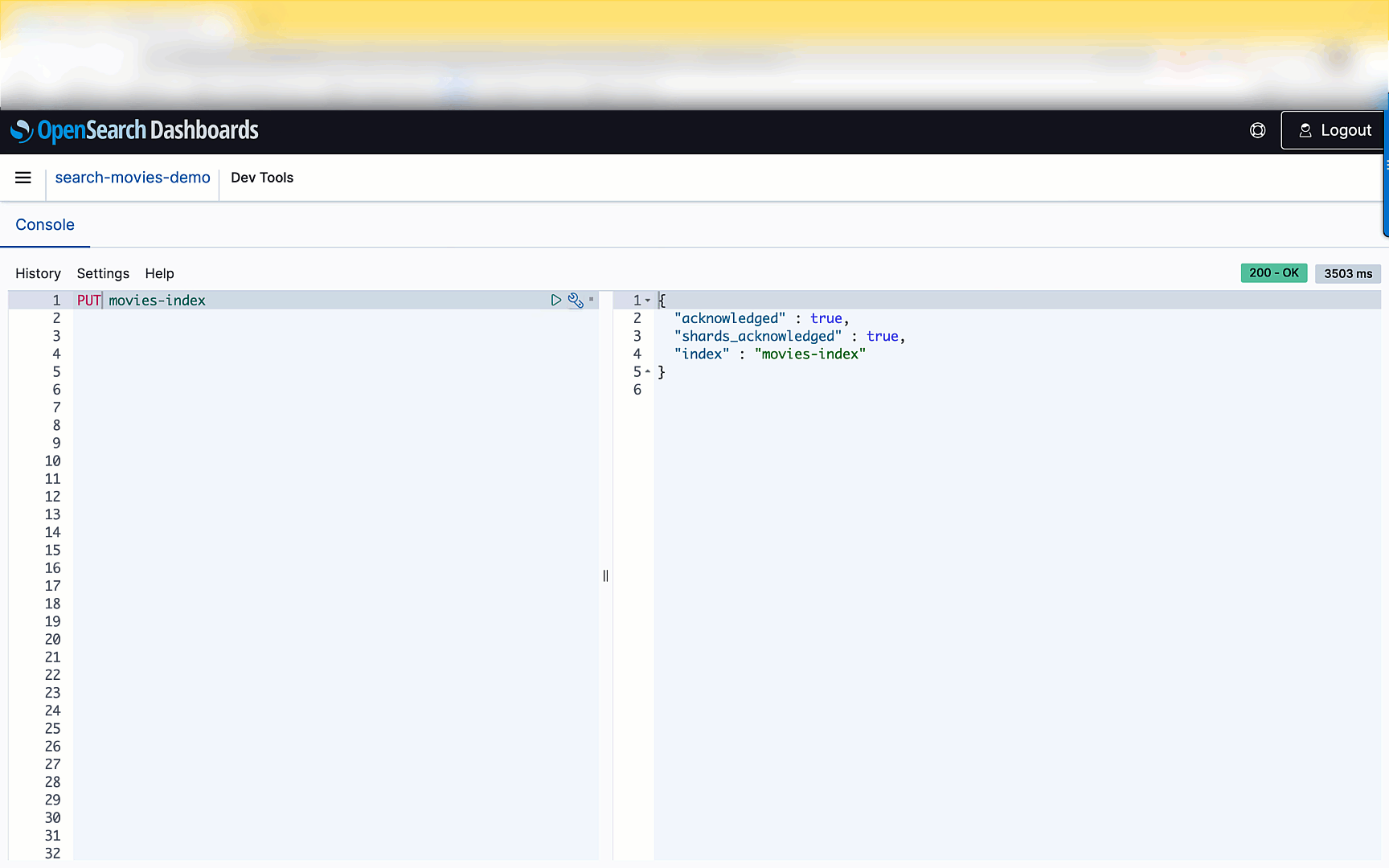
After the index is created, you can ingest documents into the index. OpenSearch provides the option to ingest multiple documents in one request using the _bulk request. Enter POST /_bulk in the left pane as shown in the following screenshot, then copy and paste the contents of the sample-movies.bulk file you downloaded earlier.

You have successfully created the movies index and uploaded 1,500 records into the catalog! Now let’s integrate the movie catalog with your search application.
Integrate the Lambda function with an OpenSearch Serverless endpoint
In this step, you create a Lambda function that queries the movie catalog in OpenSearch Serverless and returns the result. For more information, see our tutorial on creating a Lambda function for connecting to and querying an OpenSearch Service domain. You can reuse the same code by replacing the parameters to align to OpenSearch Serverless’s requirements. Replace <my-region> with your corresponding region (for example, us-west-2), use aoss instead of es for service, replace <hostname> with the OpenSearch collection endpoint, and <index-name> with your index (in this case, movies-index).
The following is a snippet of the Lambda code. You can find the complete code in the tutorial.
This Lambda function returns a list of movies based on a search string (such as movie title, director, or actor) provided by the user.
Next, you need to configure the permissions in OpenSearch Serverless’s data access policy to let the Lambda function access the collection.
- On the Lambda console, navigate to your function.
- On the Configuration tab, in the Permissions section, under Execution role, copy the value for Role name.

- Add this role name as one of the principals of your
movie-searchcollection’s data access policy.
Principals can be AWS Identity and Access Management (IAM) users, role ARNs, or SAML identities. These principals must be within the current AWS account.

After you add the role name as a principal, you can see the role ARN updated in your rule, as show in the following screenshot.
Now you can grant collection and index permissions to this principal.
For more details about data access policies, refer to Data access control for Amazon OpenSearch Serverless. Skipping this step or not running it correctly will result in permission errors, and your Lambda code won’t be able to query the movie catalog.

Configure API Gateway
API Gateway acts as a front door for applications to access the code running on Lambda. To create, configure, and deploy the API for the GET method, refer to the steps in the tutorial. For API Gateway to pass the requests to the Lambda function, configure it as a trigger to invoke the Lambda function.
The next step is to integrate it with the front end.
Test the web application
To build the front-end UI, you can download the following sample JavaScript web service. Open the scripts/search.js file and update the apigatewayendpoint variable to point to your API Gateway endpoint:
You can access the front-end application by opening index.html in your browser. When the user runs a query on the front-end application, it calls API Gateway and Lambda to serve up the content hosted in the OpenSearch Serverless collection.

When you search the movie catalog, the Lambda function runs the following query:
The query returns documents based on a provided query string. Let’s look at the parameters used in the query:
- size – The
sizeparameter is the maximum number of documents to return. In this case, a maximum of 25 results is returned. - multi_match – You use a match query when matching larger pieces of text, especially when you’re using OpenSearch’s relevance to sort your results. With a
multi_matchquery, you can query across multiple fields specified in the query. - fields – The list of fields you are querying.
In a search for “Harry Potter,” the document with the matching term both in the title and plot fields appears higher than other documents with the matching term only in the title field.

Congratulations! You have configured and deployed a search application fronted by API Gateway, running Lambda functions for the queries served by OpenSearch Serverless.
Clean up
To avoid unwanted charges, delete the OpenSearch Service collection, Lambda function, and API Gateway that you created.
Conclusion
In this post, you learned how to build a simple search application using OpenSearch Serverless. With OpenSearch Serverless, you don’t have to worry about managing the underlying infrastructure. OpenSearch Serverless supports the same ingestion and query APIs as the OpenSearch Project. You can quickly get started by ingesting the data into your OpenSearch Service collection, and then perform searches on the data using your web interface.
In subsequent posts, we dive deeper into many other search queries and features that you can use to make your search application even more effective.
We would love to hear how you are building your search applications today. If you’re just getting started with OpenSearch Serverless, we recommend getting hands-on with the Getting started with Amazon OpenSearch Serverless workshop.
About the authors
 Aish Gunasekar is a Specialist Solutions architect with a focus on Amazon OpenSearch Service. Her passion at AWS is to help customers design highly scalable architectures and help them in their cloud adoption journey. Outside of work, she enjoys hiking and baking.
Aish Gunasekar is a Specialist Solutions architect with a focus on Amazon OpenSearch Service. Her passion at AWS is to help customers design highly scalable architectures and help them in their cloud adoption journey. Outside of work, she enjoys hiking and baking.
 Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.
Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.