AWS HPC Blog
Leveraging Slurm Accounting in AWS ParallelCluster
The Slurm job scheduler can collect accounting information for each job (and job step) that runs on your HPC cluster into a relational database. By default, in AWS ParallelCluster, job information is only persisted while the job is running. In order to persist job information after completion we need to enable Slurm accounting.
With this capability enabled, you can find out operational details about running, terminated, and completed jobs. You can set quality of service levels for specific jobs, partitions, and users, as well as implement fair-share scheduling.
Importantly, you can also use Slurm accounting to meter and limit consumption. And, you can use it to run detailed post-hoc usage reports, which can be helpful for billing and usage efficiency analysis.
AWS ParallelCluster 3.3.0 can configure and enable Slurm accounting for you automatically. You provide a database URI and credentials and ParallelCluster can then manage the undifferentiated heavy lifting to set up accounting when it creates your HPC cluster. This post will show you how to use this new feature.
How to Set Up Slurm Accounting
Slurm uses a MySQL or MariaDB-compatible database management server, which you provide, to hold accounting data. You can use a self-managed server, or leverage a hosted solution like Amazon Aurora.
Once you have set up your database server, make sure that the slurmdbd service running on your cluster head node can communicate with it. The means the database server allows inbound traffic from the head node, and the head node allows outbound traffic to the database. You can accomplish this with security groups attached to the head node, and if appropriate, to the instance where the database is running. Next, store the password for the database administrator account as a plaintext secret in AWS Secrets Manager so AWS ParallelCluster can access it securely.
In case you are new to AWS Secrets Manager, this process is illustrated below. First, navigate to AWS Secrets Manager in the AWS Management Console, select Store new secret, and choose Other type of secret (Figure 1a). Enter the database password as a plain text value, making sure to choose a strong password. On the next screen, give the secret a distinct, descriptive name (Figure 1b), then finish up by navigating through the next two screens (which give provide additional options) and choose Store. Finally, select your new secret by its distinct name to view a detail page where you can find its ARN (Figure 1c), which you can use in configuring AWS ParallelCluster Slurm accounting.
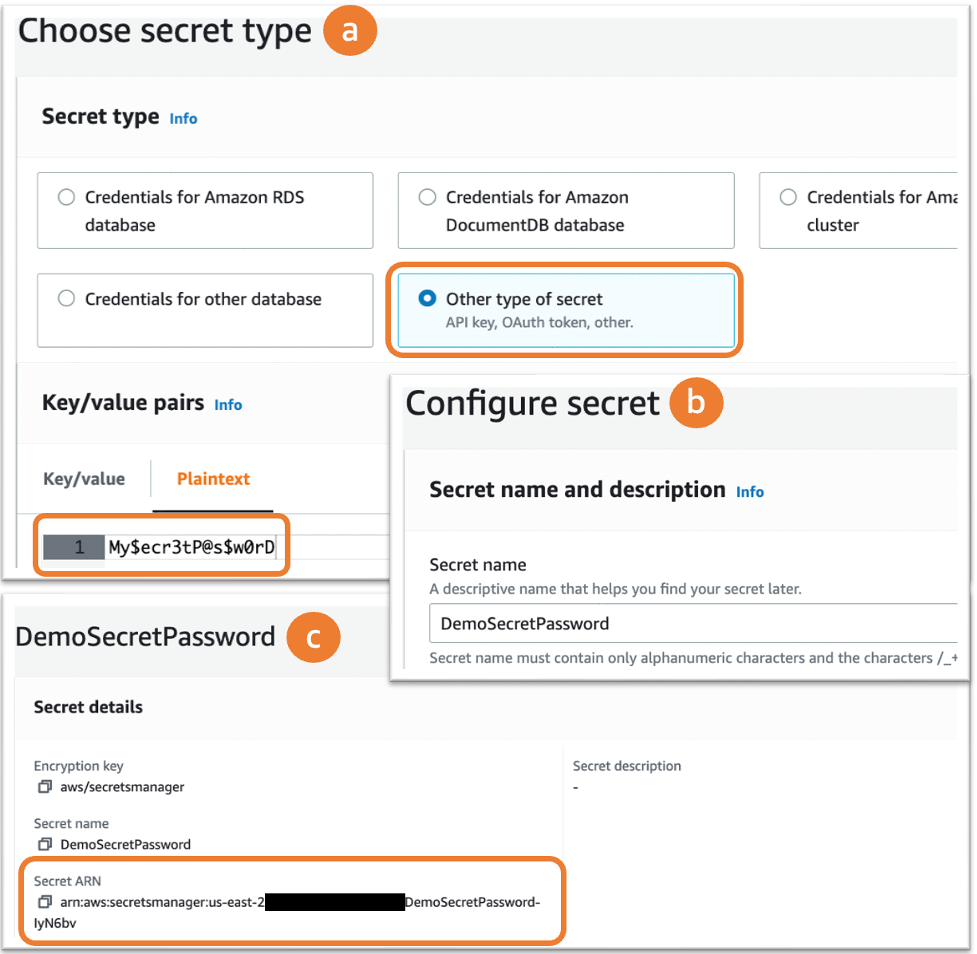
Figure 1. Creating a plaintext password with AWS Secrets Manager
Create a serverless accounting database
The AWS ParallelCluster documentation includes a detailed tutorial on how to set up an Amazon Aurora database and use it with Slurm accounting. You can deploy your database in a high-availability configuration with its communications secured by TLS encryption. Briefly, the sequence of actions is:
- Create the VPC and subnets that will be shared by your cluster and the Amazon Aurora server (you can also use an existing VPC and subnets).
- Run the provided AWS CloudFormation template to create an Amazon Aurora database.
- Use the outputs from running the AWS CloudFormation stack (Figure 1) to configure AWS ParallelCluster.
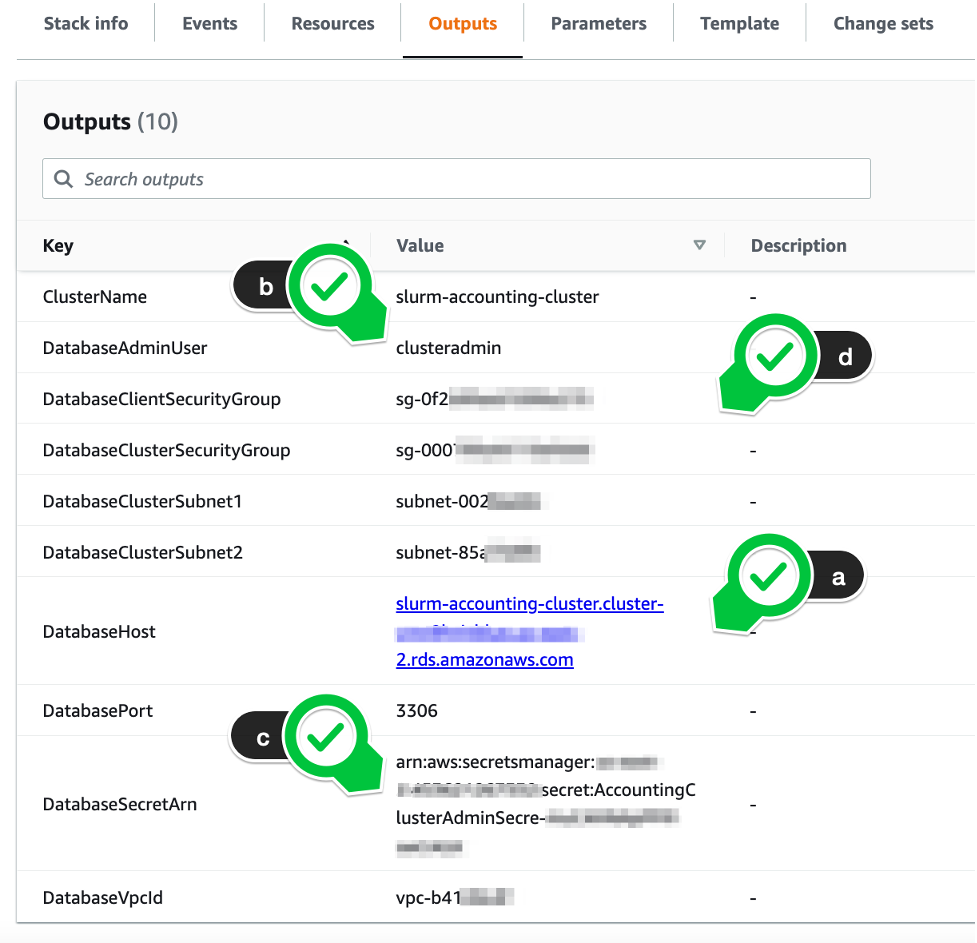
Figure 2. Outputs from the provided Amazon Aurora stack required to configure AWS ParallelCluster
Configure AWS ParallelCluster
To use Slurm accounting with ParallelCluster, you will need to create a new cluster. Update to or install ParallelCluster to version 3.3.0 following this online guide. Create a new cluster configuration file (or update an existing one) as described below, then use that configuration to create a new cluster.
Slurm accounting adds an additional service, slurmdbd, to the cluster head node. This service must remain responsive for the cluster to operate effectively. Therefore, we recommend using a slightly larger instance type than the AWS ParallelCluster default so your head node has adequate resources to run all its services. In the examples below, a t2.medium instance is selected. If you’re already using a larger instance type for your head node, you don’t need to worry about this.
ParallelCluster CLI
If you’re using the AWS ParallelCluster command line tool, add values from the AWS CloudFormation stack output to the HeadNode/Networking/SecurityGroups and Scheduling/SlurmSettings/Database config file sections as illustrated here:
HeadNode:
InstanceType: t2.medium
Networking:
SecurityGroups:
- sg-0f2XXXXXXXXX
Scheduling:
Scheduler: slurm
SlurmSettings:
Database:
Uri: slurm-accounting-cluster.cluster-XXX.rds.amazonaws.com
UserName: clusteradmin
PasswordSecretArn: arn:aws:secretsmanager:REGION:ACCOUNT:XXXXXX-XXXX
Four AWS CloudFormation stack outputs are required:
- DatabaseHost (Figure 2a) corresponds to the database server
Uri. If you are using a non-default port (something other than 3306), inline the port number in the URI. - DatabaseAdminUser (2b) pairs with the database server
UserName. You will have set this when running the AWS CloudFormation stack. - DatabaseSecretArn (2c) goes in the database
PasswordSecretArn. Note that you cannot use a plaintext password here. It must be stored in AWS Secrets Manager and retrieved from there. AWS ParallelCluster adds the requisite AWS Identity and Access (IAM) permissions to fetch this secret from the head node so no changes to your IAM configuration are needed. - DatabaseClientSecurityGroup (2d) is included in the head node’s
SecurityGroups, along with any others your cluster needs to operate. This is essential to permit your cluster to contact the database server.
ParallelCluster Manager UI
The configuration workflow is similarly if you’re using ParallelCluster Manager.
In your new cluster’s Head Node Properties, the stack DatabaseHost maps to Database (Figure 3a), DatabaseAdminUser to Username (3b), and DatabaseSecretArn to Password (3c). Add DatabaseClientSecurityGroup to the head node’s Additional Security Groups (3d).
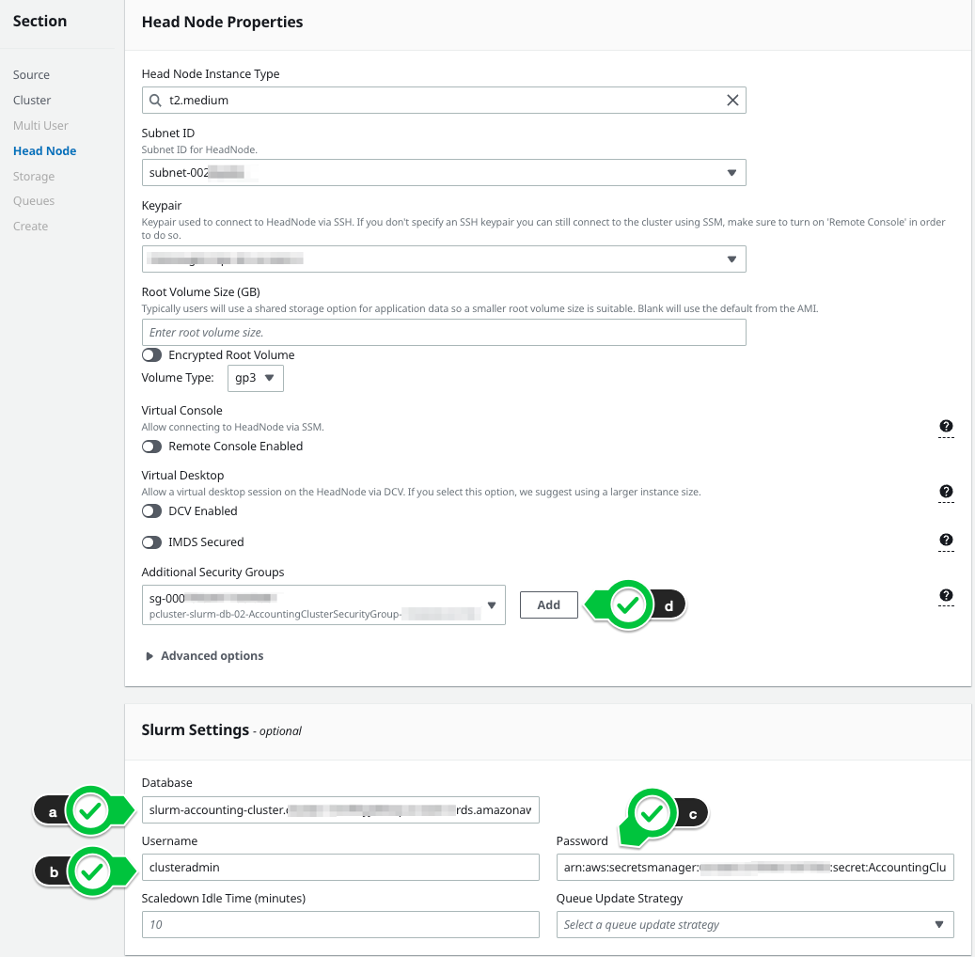
Figure 3. Configuring a new cluster with Slurm accounting using ParallelCluster Manager
Finally, launch your cluster, either using the pcluster command line tool or ParallelCluster Manager. When the cluster finishes launching, it will be ready to use Slurm accounting.
Using Slurm Accounting in AWS ParallelCluster
If you are using ParallelCluster Manager, you will have access to some accounting features right in the web interface. In the cluster detail pane, choose the Accounting tab to get a filterable list of all jobs run on the cluster (Figure 4).
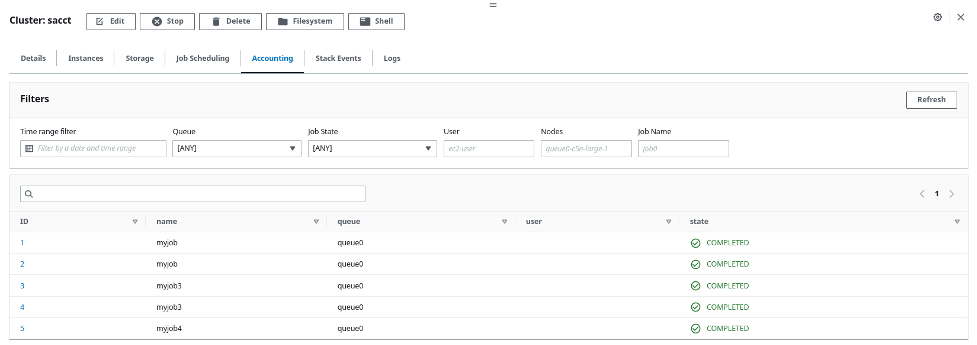
Figure 4. The ParallelCluster Manager jobs list view can be filtered by date, queue, user, job size, and more.
Choose any job by its ID to see details about that job, including what nodes it ran on, how long it ran, and what resources it used (Figure 5).
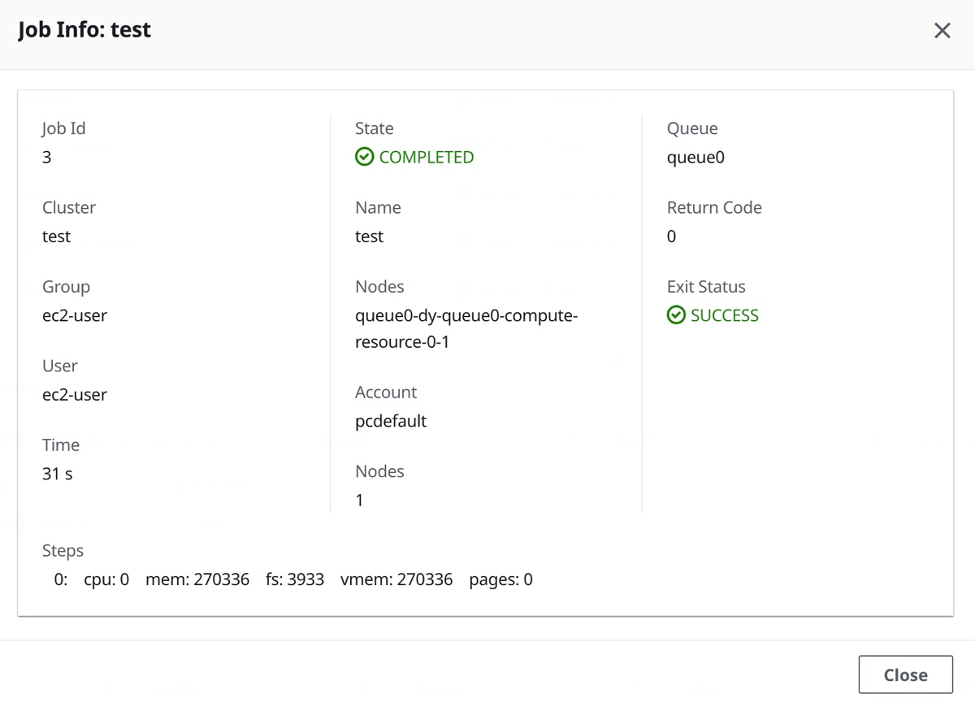
Figure 5. Accounting details for a single job shown by ParallelCluster Manager
For more in-depth queries and accounting functions, log into your cluster using SSH or AWS Systems Manager. You will find that Slurm accounting-related commands such as sacct, sacctmgr, and sreport are installed and are immediately useful.
saact
For instance, the sacct command lets you pull up accounting information for a specific job (or jobs). Here we can see that the job with id 2 was submitted to the hpc partition using the pcdefault account. It ran to a COMPLETED state, exiting with POSIX code 0. You can get more in-depth information by passing the --long flag and format the output as JSON with --json.
You can also query by date and partition. In the following queries, jobs run since the start of November 2022 in the hpc and htc partitions are shown.
saactmgr
Next, the sacctmgr command lets you for manage users, accounts, quality of service, and more. For example, you can list all known users on a cluster with sacctmgr show user.
You can also use it to create and manage users, accounts, quality of service settings, and fairshare values. Its usage is covered in detail in the Slurm documentation.
sreport
Finally, the sreport command lets you create retrospective reports, scoped by cluster, job, or user. For example, here is an example of a report of account usage expressed in CPU hours, by user, since the start of November. In this report, we see that the ec2-user has used a total of 6.2 compute hours in the pcdefault account.
It is beyond the scope of this article to cover everything you can do with Slurm accounting. However, you can find an in-depth review of Slurm accounting from the SchedMD team (the developers of Slurm) on the HPC TechShorts YouTube channel.
Conclusion
Slurm accounting brings additional flexibility, transparency, and control to operating a high-performance computing cluster, especially when multiple users or projects share the system. AWS ParallelCluster 3.3.0 helps you simplify and automate installation of Slurm accounting, asking you to provide just four configuration variables.
The new automation is designed to work equally well with on-premises, self-managed, or AWS-hosted databases, providing additional avenues for integrating AWS ParallelCluster into your information systems architecture. You’ll need to update your AWS ParallelCluster installation and configure a MySQL-compatible database to use this new capability.
We would be delighted to hear what you are building with Slurm accounting on AWS ParallelCluster. Reach out to us on Twitter at @TechHPC with your experiences and any ideas about how we can make AWS ParallelCluster better.