Exploring Apache Flink & AWS KDA: Realtime data streaming
Engineers share their experience building realtime data streaming apps with Apache Flink and AWS Kinesis Data Analytics.
This blog was authored by Rohan Barman and Ricky Cheuk, members of the Card Tech Team
Capital One constantly embraces modern technologies to efficiently process petabytes of financial transactions. Real time applications are vital to meet our customer’s growing demand for customized experiences in real time. We recently partnered with the AWS team to build scalable and industry leading real time streaming applications.
Our team specifically used Spark batch processing jobs, but observed that data pipelines become less efficient as data size increases. Some hourly batch processes lagged behind nominal completion time. As a patch solution, we constantly tuned the clusters to catch up with the increased demand in processing power.
To address this, we looked into different solutions to improve the efficiency of our current process, as well as to reduce the effort to maintain while the data scales. Our goal was to use managed services, like AWS Kinesis Data Analytics (KDA) and AWS Aurora to perform real time data processing. We built a proof of concept to judge if KDA with Flink is a possible solution.
In this article, you will learn about building Flink with AWS, plus:
- What Flink and KDA are
- How to build an application to consume Kafka stream using Flink in KDA
- Our experience and challenges while building the application
Why Flink/KDA?
There are various streaming technologies available in the market. We chose Flink due to its integration in managed AWS services and our familiarity with Apache products.
Flink
- Works in real time
- Memory management system eliminates memory spikes
- SQL based transformations
Kinesis Data Analytics (KDA)
- AWS managed version of Flink
- Handles scaling
- Easy configuration
- Integrates with other AWS services
Flink setup
We used the PyFlink Python Flink API to build our solution. Even though the Java/Scala APIs are more mature and allow for more customization, we found the Python APIs sufficient for our use case.

Basic workflow of a Flink application

Our application architecture overview
A Flink program consumes data from the source, applies different transformations, and then writes data to the sink. In our program, the source is a Kafka stream and destination sink is AWS Aurora database.
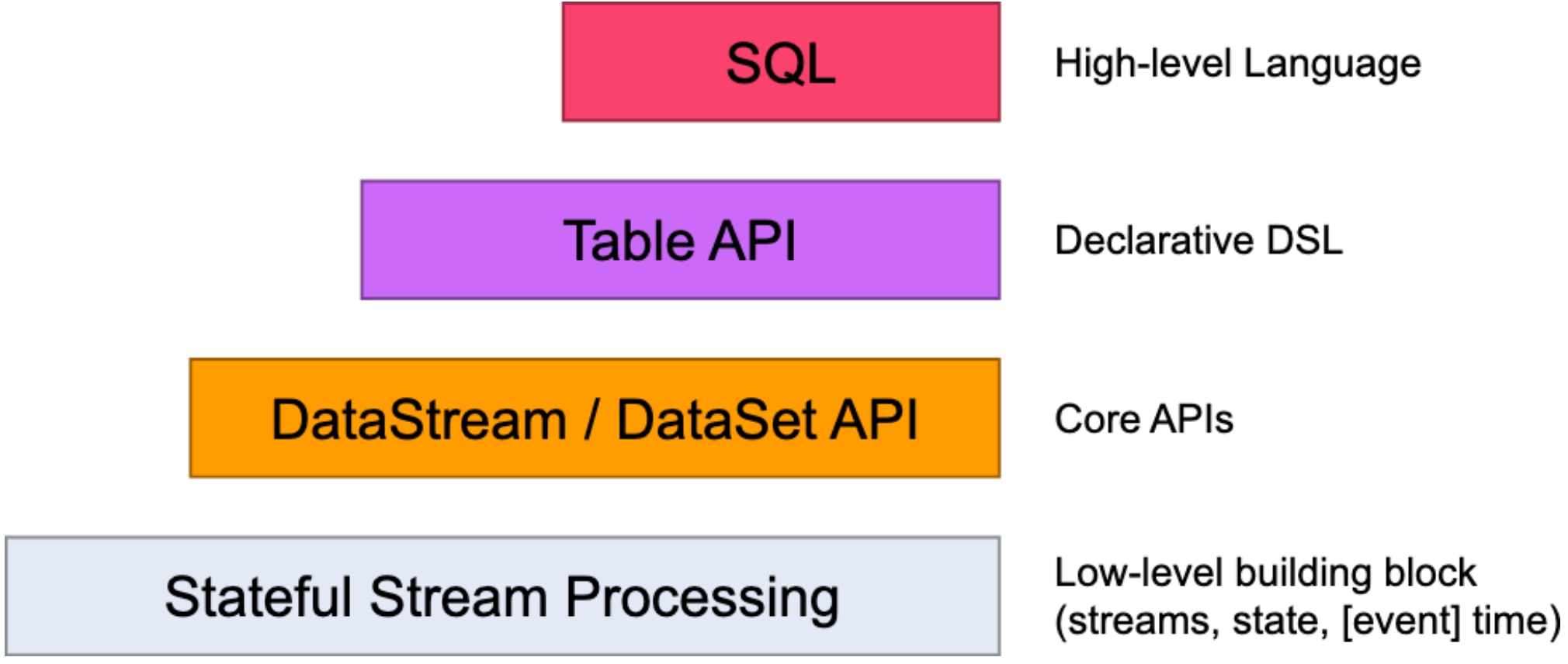
Building blocks of Flink APIs
Flink programs can be written with the Table API, DataStream API, or a combination of both. Each API has its own way of reading data sources, executing transformations, and writing to data sinks. We will focus on the Table API because it lets us work with SQL queries.
Flink environment setup
We use Flink version 1.13 because it’s the latest version that KDA supports.
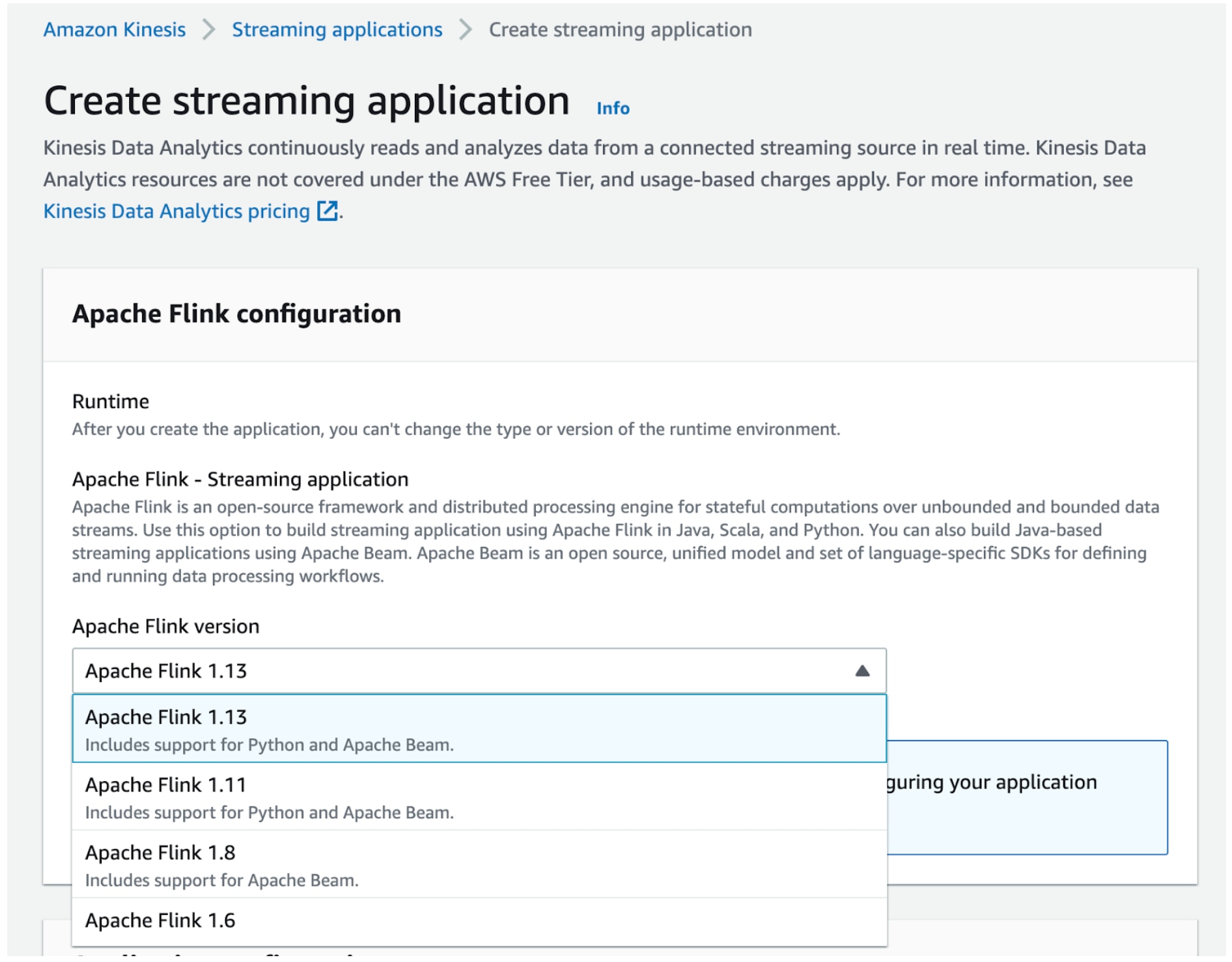
KDA configuration page
The first step is to create a Stream Table environment.
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
# Initialize Flink env
Env = StreamExecutionEnvironment.get_execution_environment()
# Create table env (similar to Spark sessions in Spark)
T_env = StreamTableEnvironment.create(stream_execution_environment=env)
Kafka/data source setup
The next step is to set up your data source. Flink can consume data sources such as Kafka, filesystem, JDBC databases, and elastic search. Let’s focus on consuming a Kafka stream.
We need a Flink SQL DDL query with the Kafka connector to consume Kafka streams. The query requires stream metadata such as bootstrap servers, topic name, and which columns to extract from the stream.
The below query creates a table called “my_source.” It consumes raw records from a Kafka stream and stores the records as a BYTES column in the table called “message.”
The Kafka stream has a SSL security layer so we have to add SSL related configuration (keystore location, password, and truststore location). Review the official Kafka consumer configs for all possible parameters.
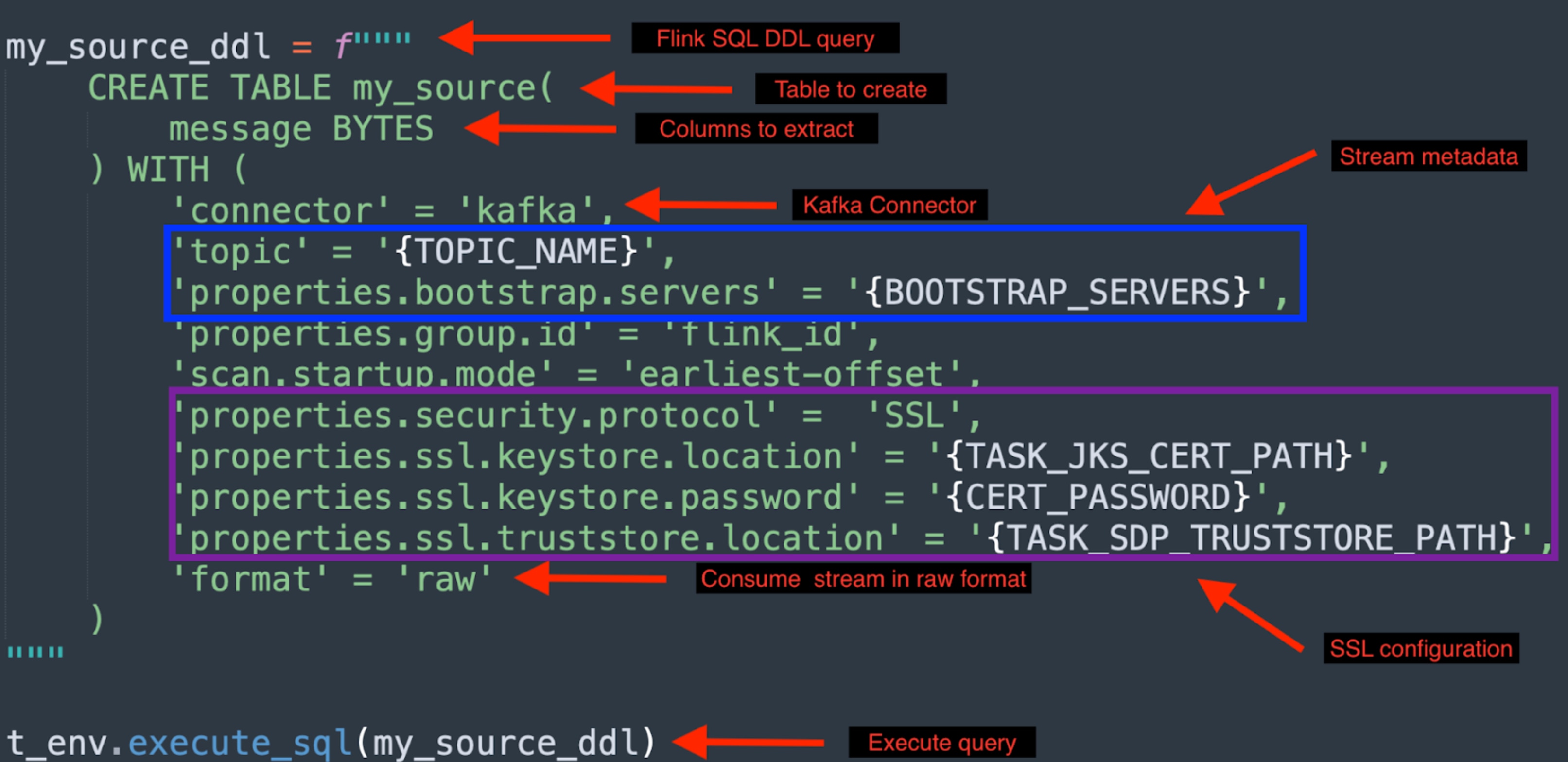
Example of a Flink DDL query that consumes a Kafka stream
It is best practice to use the data format with the connector that matches the data format of the source. Our Kafka stream contains custom data types which are not supported by Flink with Flink Confluent Avro format, hence we need to read raw byte messages from the stream and create an UDF that decodes the raw messages and returns structured output as a workaround. We will discuss this further in the “User-defined function” section.
Aurora/data sink setup
Now let’s move on to the data sinks. Similar to data sources, Flink allows you to write to data sinks such as Kafka, filesystem, JDBC databases, and elastic search. Let’s focus on JDBC databases.
Flink’s JDBC connector is the standard way to write data to database sinks. We need a Flink SQL DDL query with the JDBC connector to write to the Aurora database. The query requires table metadata such as database url, table name, credentials, etc. We also list out all the columns to write.
The below query creates a sink table called “my_sink”. The contents of this table will be written to the Aurora database table specified with the sink metadata. The schema of the Flink table must match with the schema of the actual sink database table.
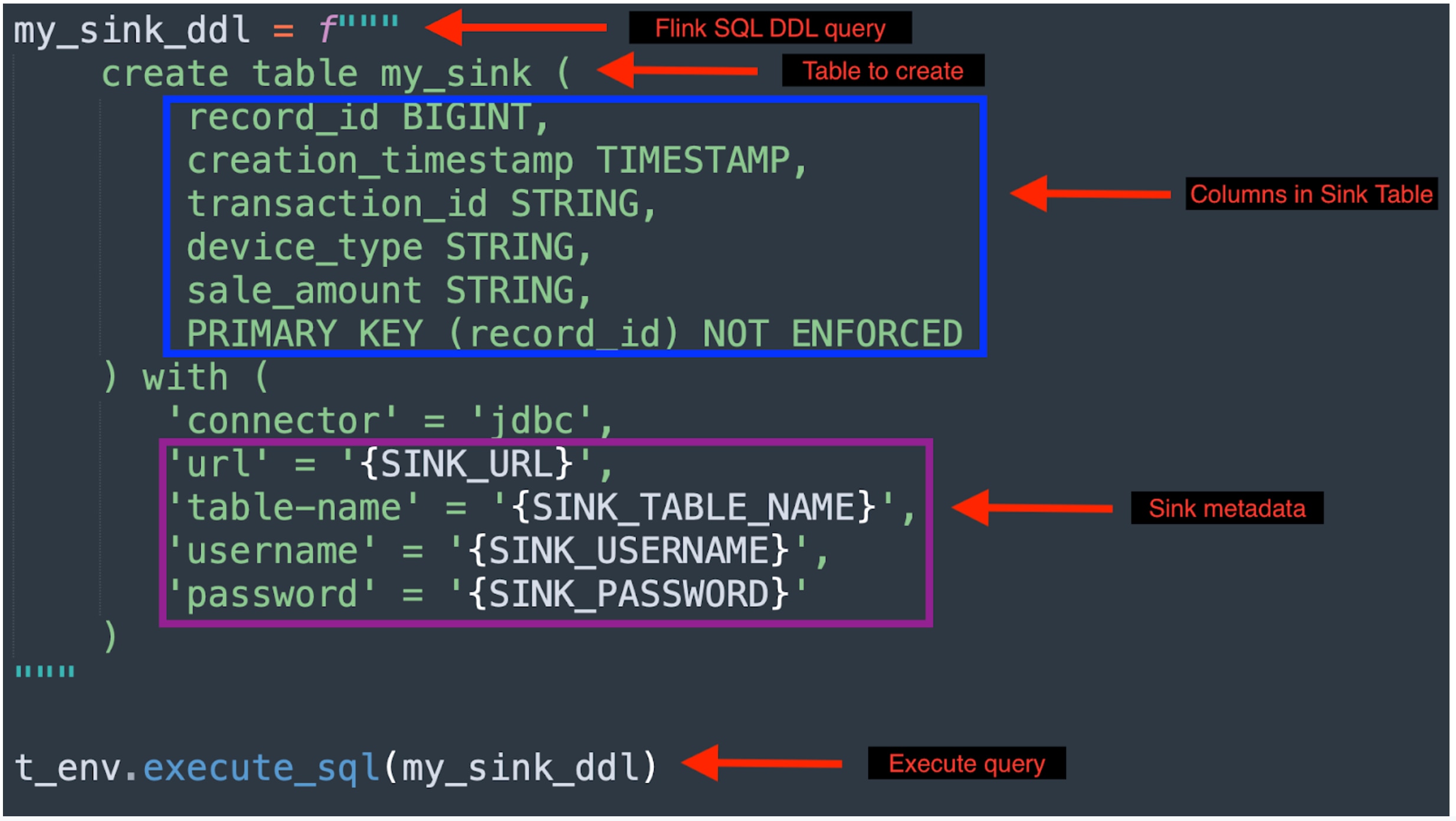
Example of a Flink DDL query that writes to Aurora database table
User-defined function (UDF)
UDFs are extension points to call frequently used logic or custom logic that cannot be expressed otherwise in queries.
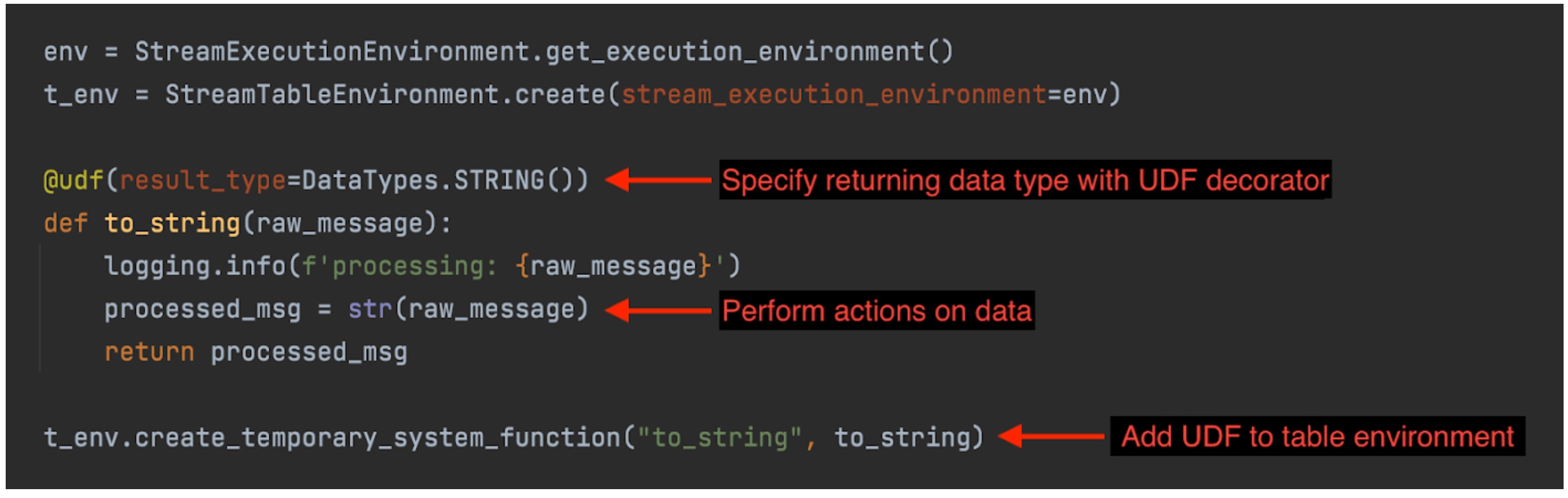
Example of a Flink UDF
As discussed in the “Kafka/Data Source Setup” section, we need a custom UDF to decode raw byte messages to a structured output. The Kafka source is built with the Confluent-Kafka platform and thus we need to use the Confluent-Kafka Python library to decode messages properly.
The below code creates a Confluent-Kafka MessageSerializer by specifying the stream’s schema registry url and certification path. The UDF uses the MessageSerializer to convert the raw bytes message from stream to a Python dictionary. Then it has custom code to extract fields from the dictionary. The UDF decorator specifies that the UDF output is a structured row with 5 fields.
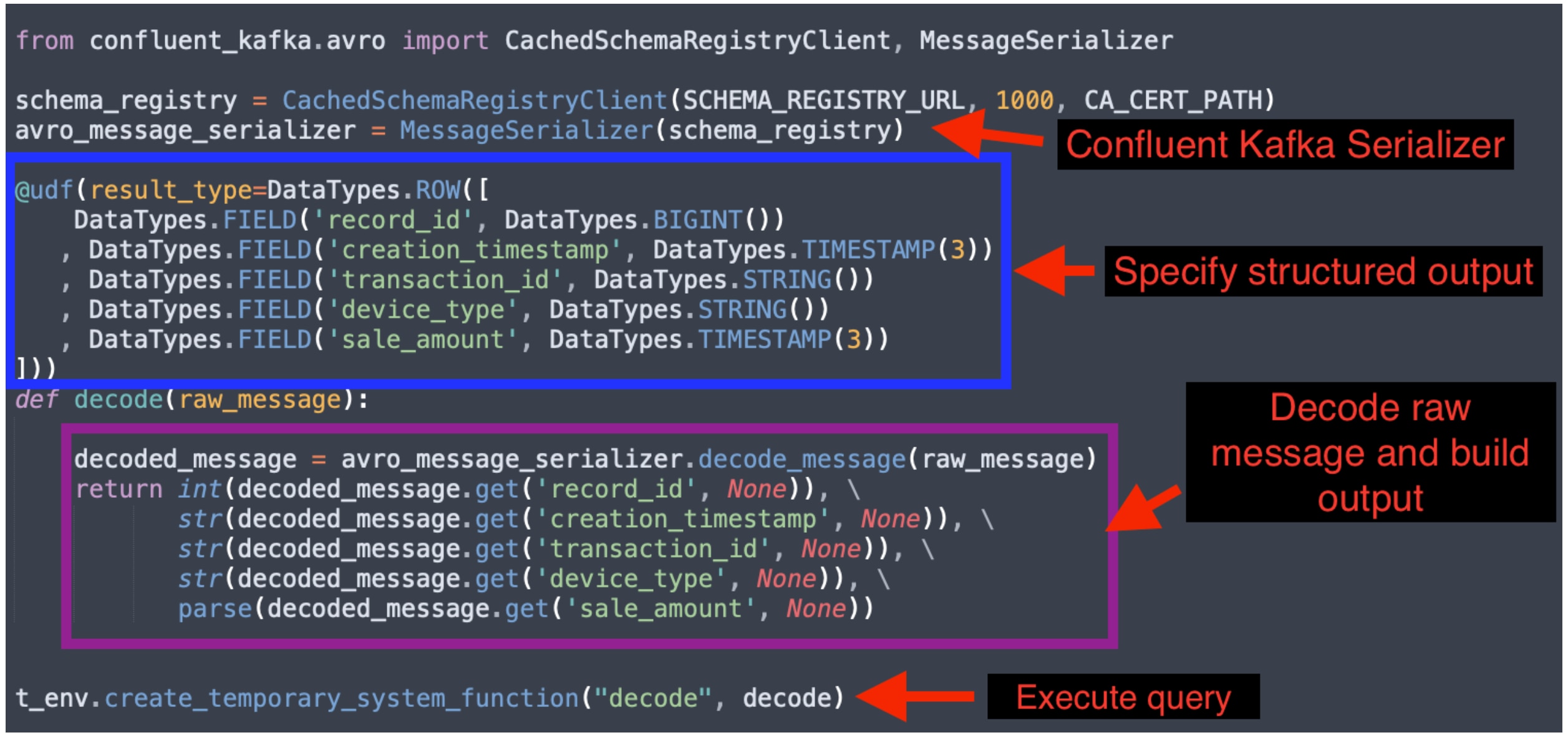
Example of Flink UDF with deserialization logic
Transform data
Having the data sources and sinks ready, we now work on the transformation layer. Flink Table API allows us to write all transformations with SQL queries.
The below query transforms the source table and loads into the sink table. It applies the above UDF to convert raw bytes from source table into a structured table called ‘decoded_message’, applies SQL functions, and then inserts transformed data into the “my_sink” table. In our example, “my_sink” is an Aurora database table, so all the transformed data is written to Aurora.

Example of Flink query that transforms and loads data from source to sink
Flink cluster architecture in KDA
Let’s first learn about the Flink cluster architecture, which will help you understand how Flink works and explain some workarounds we need to do when using KDA.

Flink cluster architecture
Job managers
Job managers manage task slots, responsible for resource allocation and provisioning in a Flink cluster. Task managers contain task slots which subtasks can be run on.
Job managers and task nodes do not share the same file storage in KDA. When users upload the code package, it will be uploaded to the job manager only. Although we can use KDA runtime properties (see “KDA setup” section) to pass files into task nodes, every task node has a different file path name based on the task IDs which cannot be explicitly specified in our code.
To connect to self-managed Kafka streams, we need some workarounds to drop the SSL certificates into worker nodes. One way is to alter the Flink Kafka connector, to drop the certificates before connecting to Kafka servers. AWS has open-sourced this workaround, we will discuss further in the next section.
Uber/fat jar
Since KDA and Flink cluster submissions only take one jar resource, we need to bundle all Java resources for Flink connectors and other required utilities.

Combining multiple jars into an uber jar
We utilize the open-sourced custom Kafka connector created by the AWS team to drop the SSL certificates into worker nodes to connect to the source stream. This custom connector saves certificates into the “/tmp” folder - a fixed path we can specify in Flink code.
Creating uber/fat jar with AWS open-sourced Kafka connector
- Download the AWS custom Kafka connector and put it inside project.
- Include certs under the “src/main/resources/” folder.
- Change pom.xml to update dependency and versions if needed. (In our example, we added flink-jdbc connector, postgresql dependency and maven-shade-plugin transformers.)
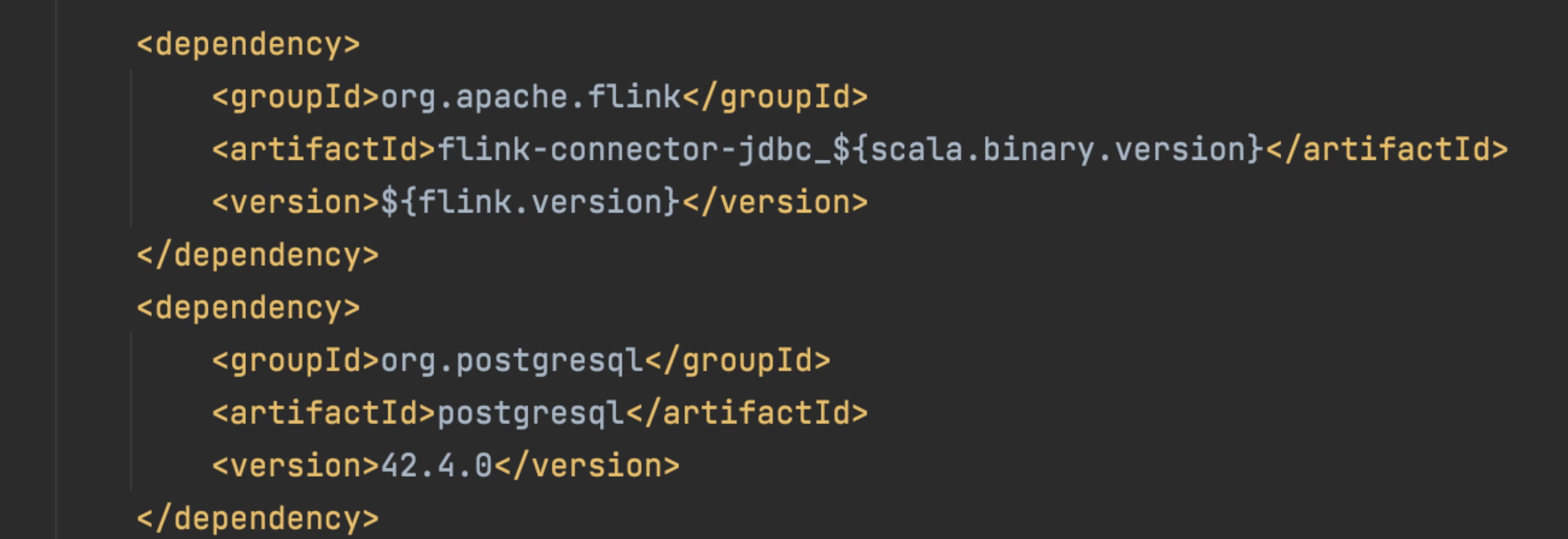
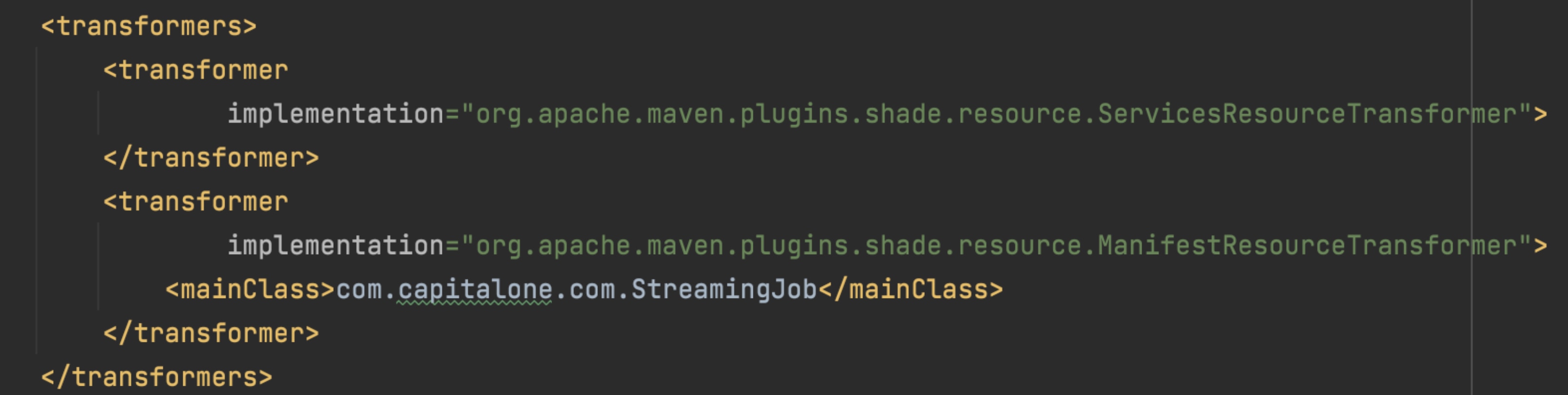
See this document for more details on maven dependencies. (Note: The linked documentation is for the latest stable Flink version. Version 1.13 does not include the correct maven-shade-plugin setup.)
- Run “mvn clean package“
- The generated jar file “TableAPICustomKeystore-0.1.jar” will be saved under “target/” folder
Flink testing with local cluster submissions
The best way to test a Flink job is to submit it to a local cluster (Official guide). It might be tempting to run a Flink job directly from an IDE, but there are more configuration and monitoring options with a cluster.
Steps
- Install Java version 8 or 11.
- Download Flink from https://flink.apache.org/downloads.html and extract.
- Modify “conf/flink-conf.yaml” if needed (e.g., to change default Flink dashboard port 8081 to other ports).
- Start cluster with ./bin/start-cluster.sh.
- Submit Python job with ./bin/flink run --python <path to program>. (Review supported pyFlink options.)
- Visit Flink Dashboard UI at http://localhost:8081/ to monitor jobs
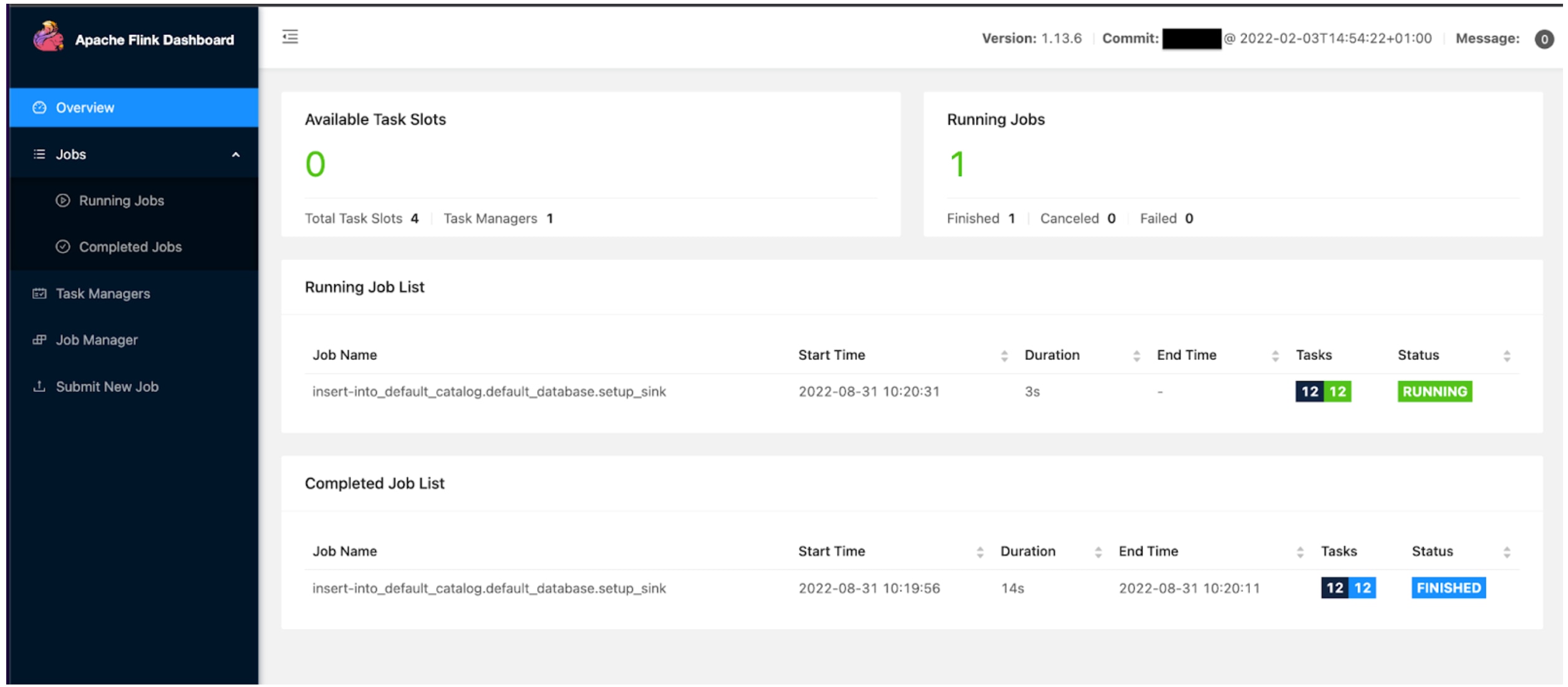
Flink dashboard
KDA setup
Once we have a successful job running in a local cluster, we run our job in KDA. Below are key steps we took to package our code, create a Flink application, and properly configure.
Packaging code
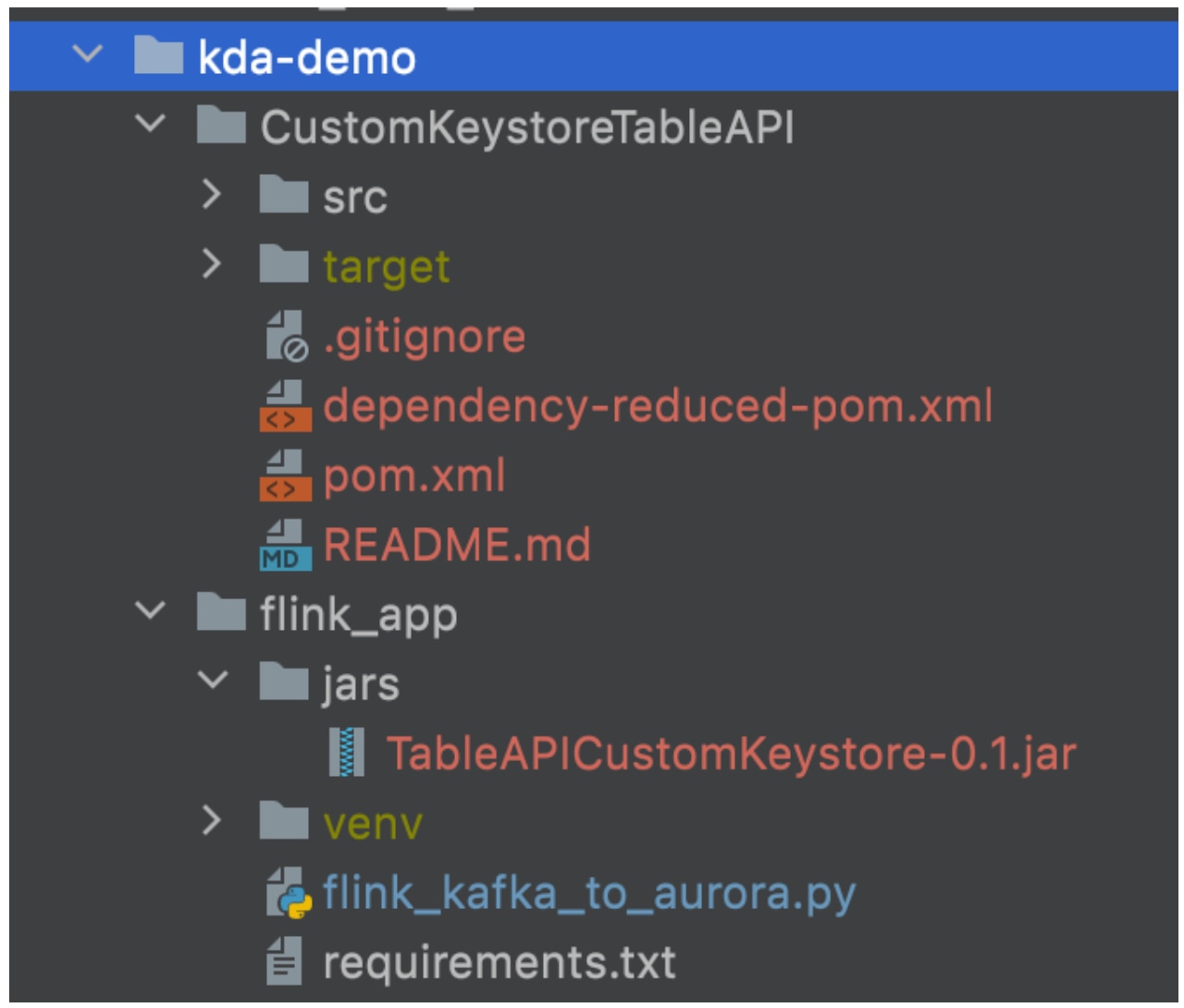
File structure example
1. Review the “Uber jar” section if jar dependencies or SSL certs change
2. Since our example uses a Confluent-Kafka Stream
a. Install Python libs
i. Python -m venv venv
ii. Source venv/bin/activate
iii. Pip install confluent-kafka
b. Modify venv/lib/python3.7/site-packages/confluent_kafka, because KDA machines do not have librdkafka installed (more details in “Learnings” section)
i. Remove all directories except avro/
ii. Delete everything in ssl_utils/confluent_kafka/__init__.py
iii. Delete everything in ssl_utils/confluent_kafka/avro/__init__.py
Creating KDA application
Please review the AWS detailed instructions for creating KDA applications.
PyFlink runtime properties
PyFlink applications have a special application property group called “kinesis.analytics.flink.run.options”, which specifies the code files and dependencies.
| Group | Key | Comment |
|---|---|---|
| kinesis.analytics.flink.run.options | jarfile | {Required} Java dependencies |
| kinesis.analytics.flink.run.options | python | {Required} pyFlink Code |
| kinesis.analytics.flink.run.options | pyArchives | {Optional} other files used in code, e.g. ssl certificates to connect to Kafka |
| kinesis.analytics.flink.run.options | pyFiles | {Optional} Python libraries needed, this will add the specified path to PYTHONPATH environment variable |

KDA console runtime properties example
Using Flink and KDA: What we learned
We have learned many things while working on this project as it’s our first time working with Flink and KDA. Given both technologies are relatively new, we implemented a few workarounds to get the app working.
-
KDA does not have options to directly upload SSL certs to task nodes directly
-
AWS team created open-sourced custom Kafka connector
-
-
KDA machines do not have librdkafka installed
-
Python confluent-kafka library is a wrapper around a C/C++ client library librdkafka. Our example required confluent-kafka library to decode source messages
- Removed unneeded submodules in confluent-kafka, only keep code needed for decoding
-
-
KDA/Flink clusters only takes in one jar as the Java resource
-
Created an Uber/Fat jar with all Java dependencies/connectors
-
-
Dealing with custom data types not supported by Flink
-
Consumed stream with raw format
- Created a custom UDF that decodes raw message
-
KDA/PyFlink pros and cons
Flink and KDA provide many benefits on building a real time streaming application. We see both KDA and Flink have room for improvements, and the cons will most likely be addressed as the technologies become more mature.
Pros
- Flink works in real time.
- Other technologies like Spark Structured Streaming process data in small batches to get near real time
- Flink UDF provides flexibility for users
- Extension points to call frequently used logic or custom logic that cannot be expressed otherwise in queries
- KDA is a managed service
- No need to manage EMR clusters for scaling and vulnerability management
Cons
- High development cost
- For data sources with custom data types, you have to create a custom UDF to deserialize data and manage your own version of the Confluent-Kafka Python library in KDA Flink. Also, SQL has different keywords than Spark SQL.
- Not as mature
- Python Flink APIs are not as complete as the Java APIs, learning resources are not as complete compared to Spark, and KDA platform is relatively new.
Processing jobs in real time with Flink
Outgrowing our traditional Spark batch processing design led us to explore a proof of concept of real time processing jobs with Flink. We deployed Flink applications to KDA that consume data from Kafka streams and write transformed data to AWS Aurora database. We faced several challenges because KDA is still a fairly new service and Flink’s Python APIs are not as mature as its Java counterparts. Fortunately we received great support from AWS. Together we collaborated on developing necessary work-arounds and applying best practices.
We highly recommend exploring Flink with KDA. Flink is a strong solution for real time data pipelines. It has a variant of SQL that is easy to pick up for most data engineers and has connectors for most common data sources and sinks. We also recommend deploying Flink applications to KDA. It is a self managed service so you can focus on developing Flink applications while KDA internally handles scaling and vulnerability management.
---
This blog was authored by Rohan Barman and Ricky Cheuk, members of the Card Tech Team
Rohan Barman, Data Engineer, and Ricky Cheuk, Software Engineer, work on the Card Tech team and helped build real time data streaming applications with Apache Flink and AWS Kinesis Data Analytics.


