Member-only story
Building Data Lakes on AWS with Kafka Connect, Debezium, Apicurio Registry, and Apache Hudi
Learn how to build a near real-time transactional data lake on AWS using a combination of Open Source Software (OSS) and AWS Services
Published in
21 min readFeb 28, 2023
Introduction
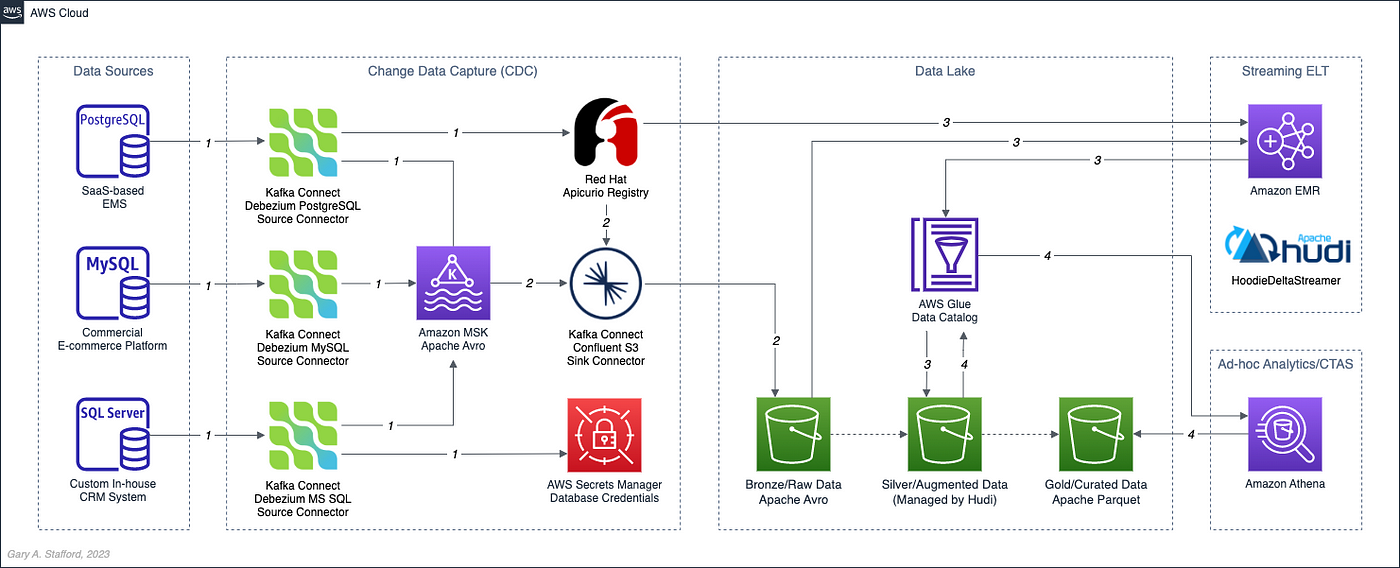
In the following post, we will explore one possible architecture for building a near real-time transactional data lake on AWS. The data lake will be built using a combination of open source software (OSS) and fully-managed AWS services. Red Hat’s Debezium, Apache Kafka, and Kafka Connect will be used for change data capture (CDC). In addition, Apache Spark, Apache Hudi, and Hudi’s DeltaStreamer will be used to manage the data lake. To complete our architecture, we will use several fully-managed AWS services, including Amazon RDS, Amazon MKS, Amazon EKS, AWS Glue, and Amazon EMR.
Source Code
The source code, configuration files, EMR Notebook, and a list of commands shown in this post are open-sourced and available on GitHub.

