November 30th - Instalment #46
Week No.46 and this week marks the beginning of re:Invent 2020 so expect a lot of re:Invent related content in this episode and the next couple. re:Invent has not stopped the relentless march of great open source blog posts, projects and more this week, and we have some great stuff this week including...the launch of Amazon Managed Workflows for Apache Airflow, an unmissable post on Rust from Matt Asay, a bumper selection of Elasticsearch updates this week, a new project from the Amazon Neptune team and a couple of fantastic videos, one covering AWS CDK and projen and the other kube-bench.
So, let's crack on and start with what you can expect during re:Invent.
re:Invent 2020
The Open Source track is back at re:Invent this year, with content spread across the first two weeks of the three-week virtual experience. This year, the Open Source track will introduce attendees to number of open source technologies such as GraphQL, Apache Kafka, Redis, Apache Flink, and more. The track will also cover topics on app acceleration using Amplify, observability with AWS Distro for OpenTelemetry, and chaos engineering. We have put together a couple of blog posts to help you understand in more detail what these sessions are as we know you will have a lot of hard choices to make as there are so many great sessions across all the tracks. re:Invent 2020: Open Source track preview covers the open source track, and re:Invent 2020: Open source session round-up takes a look beyond the open source track at other sessions where open source is featured heavily.
This week's open source related sessions in chronological order are as follows. Sessions are typically repeated three times to accommodate the different time zones you might be in. These are all in CET so remember to add or subtract time depending on where you are.
DEC 1st
- AWS Data Hero Manrique LopezUsing Open Distro for Elasticsearch for developer analytics (6am CET - not repeated)
- OPN 201: Introduction to GraphQL (11:30pm CET)
DEC 2nd
- CON211 Red Hat OpenShift Service on AWS (6pm CET)
- OPN 201: Introduction to GraphQL (repeat, 7:30am/3:30pm CET)
- OPN 202: App modernization on AWS with Apache Kafka & Confluent Cloud (7:15pm CET)
- OPN 203: Redis 2020: Creating a Community-Driven Project (9:30 PM CET)
DEC 3rd
- OPN 204: Accelerate that App! with Amplify opensource framework (00:30am/8:30am/4:30pm CET)
- CON211 Red Hat OpenShift Service on AWS (repeat, 2am/10am CET)
- OPN 202: App modernization on AWS with Apache Kafka & Confluent Cloud (repeat, 3:15am/11:15am CET)
- OPN 203: Redis 2020: Creating a Community-Driven Project (repeats 5:30AM/1:30PM CET)
- OPN 301: Open Source Observability (7pm CET)
- CMP206 HPC on AWS: Innovating without infrastructure constraints (7:45pm CET)
- AIM404 Productionizing R workloads using Amazon SageMaker, featuring Siemens (10:15pm CET)
DEC 4th
- OPN 301: Open Source Observability (repeat, 3am/11am CET)
- CMP206 HPC on AWS: Innovating without infrastructure constraints (repeat, 3:45am/11:45am CET)
- AIM404 Productionizing R workloads using Amazon SageMaker, featuring Siemens (repeat, 6:15am/2:15pm CET)
Celebrate open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to George Pongracz, Franck Pachot, Nader Dabit, Shawn Sachdev, Daniel Pinheiro, Johny Duval, Rohit Yadav, David Boyne, Kaituo Li, Chris Swierczewski, Ekene Amaechi, Pahud Hsieh, Jaymit Bhoraniya, Connor Skennerton, Angela Wu, Piotr Westfalewicz, Danilo Poccia, Nick Minaie, Sam Liu, Matt Asay, James Sun, Gagan Brahmi, Chinmayi Narasimhadevara, Nathan Peck, Shrinath Kurdekar, Vikram Venkataraman, Kevin Wagner and Liz Rice.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest from open source projects
graph-notebook
graph-notebook is a new open source tool from the Amazon Neptune team. The graph notebook provides an easy way to interact with graph databases using Jupyter notebooks. Using this open-source Python package, you can connect to any graph database that supports the Apache TinkerPop or the RDF SPARQL graph model. These databases could be running locally on your desktop or in the cloud. Graph databases can be used to explore a variety of use cases including knowledge graphs and identity graphs.
The open-source graph notebook provides users the flexibility to run their queries and visualisation from local desktops, EC2, or EMR in addition to using the Neptune Workbench on SageMaker. It is easily installed via the Python Package Installer (PIP). You can connect to graph databases that provide an endpoint that implements an Apache TinkerPop Gremlin Server or the SPARQL 1.1 Protocol. The notebook also gives developers the power to enhance and contribute to the features in the notebook.
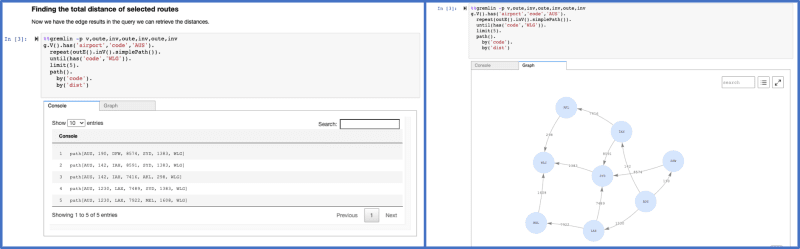
Check out the coverage in Silicon Angel from Maria Deitscher, AWS open sources Graph Notebook to make working with graph databases easier.
geneve-proxy
geneve-proxy is an open source reference application for a proxy appliance behind an AWS Gateway Load Balancer (GWLB) from Sentia Labs. They put together a blog post to help you understand what and why this project was put together. GeneveProxy - an AWS Gateway Load Balancer reference application walks you through what was built - a first party application, written in Python, which receives traffic from the GWLB, decapsulates the packet, inspects the packet, re-encapsulates it and returns it to the GWLB. Warning, contains ascii tables (which I love!)

aws-app-mesh-examples
aws-app-mesh-examples this is an open source solution to help you understand how to enable mTLS between two applications in App Mesh using Envoy's Secret Discovery Service(SDS). SDS allows envoy to fetch certificates from a remote SDS Server. When SDS is enabled and configured in Envoy, it will fetch the certificates from a central SDS server. SDS server will automatically renew the certs when they are about to expire and will push them to respective envoys. This greatly simplifies the certificate management process for individual services/apps and is more secure when compared to file based certs as the certs are no longer stored on the disk. If the envoy fails to fetch a certificate from the SDS server for any reason, the listener will be marked as active and the port will be open but the connection to the port will be reset.
awsicons
awsicons is an open source set of high-quality SVG icons for you to use in your web projects that has been forked from another project (documented in the README) by David Boyne. David has also put together this website https://awsicons.dev which is a great way to quickly find the icons you need (and in fact, was very helpful as I was looking for an icon for AWS Nitro Enclave and it was in this collection!)
s3_objects_check
s3_objects_check in an open source tool from the NCC Group that provides a white-box evaluation of effective S3 object permissions, in order to identify publicly accessible objects. It allows identifying publicly accessible objects, as well as objects accessible for AuthenticatedUsers (by using a secondary profile). A number of tools exist which check permissions on buckets, but due to the complexity of IAM resource policies and ACL combinations, the effective permissions on specific objects is often hard to assess. The tool runs fast as it uses asyncio and aiobotocore. Easy to run via the command line, with some examples to get you started.
AWS open source posts
Rust
Why AWS loves Rust, and how we’d like to help this post from Matt Asay where he shares the where (and why) of how AWS uses Rust, and talks a little of our contributions and their evolution. The stand out piece from this post is the following:
Let’s be clear: We understand that we are net beneficiaries of the exceptional work that others have done to make Rust thrive. AWS didn’t start Rust or make it the success that it is today, but we’d like to contribute to its future success. We are convinced that investing in the wider Rust ecosystem helps our customers and those who may never become our customers. That’s OK. That’s how open source is supposed to work.
Make sure you read the rest though, including some great quotes from other AWS builders and what they are doing with Rust.
Amazon CloudWatch agent
Getting started with open source Amazon CloudWatch Agent Kevin Wagner talks about the recently open sourced Amazon CloudWatch Agent and how this has allowed community contributions, enabled customisation for client-specific use cases, and provided greater level of trust and security through design and implementation transparency. Kevin provides a brief overview of use cases for CloudWatch Agent and walks through how to install and begin configuring the agent.
Amazon Managed Workflows for Apache Airflow
Introducing Amazon Managed Workflows for Apache Airflow (MWAA) Danilo Poccia announces the availability of Amazon Managed Workflows for Apache Airflow (MWAA), a fully managed service that makes it easy to run open-source versions of Apache Airflow on AWS and to build workflows to execute your extract-transform-load (ETL) jobs and data pipelines. Developers and data engineers simplify the overall process of building those ETL jobs by decomposing it into a series of smaller tasks and coordinate the execution of these tasks as part of a workflow. Apache Airflow is a popular open source platform created by the community to programmatically author, schedule, and monitor workflows. With Airflow you can manage workflows as scripts, monitor them via the user interface (UI), and extend their functionality through a set of powerful plugins. Danilo provides a good introduction and walkthrough so you can build your first workflow.

As Danilo notes, upstream compatibility is a core tenet of Amazon MWAA. Our code changes to the AirFlow platform are released back to open source.
Apache Hive
Accessing and visualizing external tables in an Apache Hive metastore with Amazon Athena and Amazon QuickSight this is a blog post and solution from James Sun, Gagan Brahmi, and Chinmayi Narasimhadevara walk you through a solution that uses Athena to query external Apache Hive tables with public COVID-19 datasets. This posts shows you how to configure a remote Hive metastore based on Amazon Relational Database Service (Amazon RDS) and MySQL with Amazon EMR, and then demonstrates how you can use a Spark step to pull COVID-19 datasets from a public repository and transform the data into a performant Parquet columnar storage format.
Apache Flink
Real-Time In-Stream Inference with AWS Kinesis, SageMaker & Apache Flink in this collaboration between Shawn Sachdev, Daniel Pinheiro, Johny Duval, and Rohit Yadav you will learn how you can use Amazon Kinesis Data Analytics for Apache Flink (KDA), Apache Flink as well as some other AWS services to address the challenges such as real-time fraud detection on a stream of credit card transaction data. They explore how to build a managed, reliable, scalable, and highly available streaming architecture based on managed services that substantially reduce the operational overhead compared to a self-managed environment, and focus on how to prepare and run Flink applications with KDA for Apache Flink applications.

Telegraf
Collecting, storing, and analyzing your DevOps workloads with open-source Telegraf, Amazon Timestream, and Grafana Piotr Westfalewicz writes on Telegraf, an open-source, plugin-driven server agent for collecting and reporting metrics and how to integrate Telegraf with Amazon Timestream, a serverless time series database service for IoT and operational applications. With the Timestream output plugin for Telegraf, you can now ingest metrics from Telegraf agent directly to Timestream and then use Grafana to visualise the metrics stored.

Elasticsearch
A bumper selection of new features and improvements this week covering Elasticsearch. The team and community has been super busy it would appear, awesome stuff.
First up we have a general update on the Amazon Elasticsearch Service that now supports open source Elasticsearch 7.9 and its corresponding version of Kibana. This minor release includes bug fixes and enhancements. In this new release, Elasticsearch added support for concurrent snapshot operations. You can now create manual snapshots while automatic snapshots are in progress. Also, you can delete multiple snapshots in a single snapshot delete call. With Elasticsearch 7.9, the default for WRITE thread pool size is changed to 10000. This change lets a single domain support indexing requests from a large number of simultaneous clients. This release also includes support for recently released features like detailed audit logging of all Elasticsearch requests, Security Assertion Markup Language (SAML) to offer single sign-on (SSO) for Kibana, and custom domain names. All these features are components of Open Distro for Elasticsearch, an Apache 2.0-licensed distribution of Elasticsearch.
Next up is news that Amazon Elasticsearch Service also introduced several security enhancements to the fine-grained access control feature. These include a revamped and improved security workflow in Kibana, and integration with Open Distro for Elasticsearch Alerting and Anomaly Detection features. The integration with Alerting and Anomaly Detection extends fine-grained access control to allow users with limited permissions to create and manage alerts and monitors. Previously, users needed administrator privileges for these tasks, but with this release, you can control how your users leverage these features. The revamped Kibana security user interface simplifies the assignment and management of fine-grained access control user permissions and role mappings while improving readability. All your existing permissions and mappings will be automatically presented in the new format. These enhancements are available on any Amazon Elasticsearch Service domain version 7.9 with fine-grained access control enabled.
If that was not enough, Amazon Elasticsearch Service also now supports Gantt charts, a new visualisation in Kibana. Users can now embed Gantt charts into dashboards to enable visualisation of events, steps and tasks as horizontal bars. The length of the bars shows the amount of time associated with an event, step or a task. Gantt charts are used to represent a series of events that contain a parent-child relationship. This can be particularly useful in trace analytics, telemetry, and monitoring use cases, in which the users need to understand the overall interaction between traces or events. Gantt charts help users manage their resources by getting an overview of the events or tasks and understanding the relationships between them. Gantt chart in Kibana is powered by Open Distro for Elasticsearch, an Apache 2.0-licensed distribution of Elasticsearch. Kibana Reports is supported on all Amazon Elasticsearch Service domains running Elasticsearch 7.9 or greater. To learn more about Open Distro for Elasticsearch and Gantt charts, visit the project website and documentation.
Following that we have this blog post from Kaituo Li and Chris Swierczewski, A deep dive into high-cardinality anomaly detection in Elasticsearch. This post takes a look into the motivation, design, and development of the high-cardinality anomaly detection (HCAD) capability within Elasticsearch, beginning with an in-depth description of the HCAD problem and its properties and then looking at the details of this solution. They follow exploring the challenges and questions we encountered during the research and development and conclude by describing the system and architecture of this solution.

And yet more! Amazon Elasticsearch Service now offers support for Remote Reindex, enabling you to migrate data from a remote cluster into Amazon Elasticsearch Service. With this feature, you can simply copy data from one cluster to another, making it easier to migrate from legacy versions of Elasticsearch. Remote Reindex also supports migrating indexes from self-managed Elasticsearch onto Amazon Elasticsearch Service, providing a simple mechanism to onboard onto the service. You can read more about this here.
We are not quite finished yet, as we also had this update from the Amazon Elasticsearch team. It now supports Piped Processing Language (PPL), a new feature that enables users to explore, discover and find data stored in Amazon ES, using a set of commands delimited by pipes (|). PPL extends Elasticsearch to support a standard set of commands that is easy for system developers, DevOps engineers, support engineers, site reliability engineers (SREs), and IT managers who are proficient with Linux or Unix to learn. PPL enables these users to begin extracting insights from their log, monitoring and observability data on day one. Read more here.
Finally, we have a video from Ekene Amaechi who takes a look at visualisation in Open Distro for Elasticsearch using a sample set of financial data. There are two videos, this is part one so make sure you check the second.
AWS Copilot
AWS Copilot is now generally available Nathan Peck announces the general availability of AWS Copilot, an open source command line interface that makes it easy for developers to build, release, and operate production ready containerized applications on Amazon ECS and AWS Fargate. This means the initial development and breaking changes are done and Copilot is ready for you to use in production. Lots of resources to get you started with Copilot, including blog posts and video walk throughs.

AWS App Mesh
Integrating cross VPC ECS cluster for enhanced security with AWS App Mesh Vikram Venkataraman writes about how you can use App Mesh for connecting, securing, and observing your cross-compute, cross-cluster, and cross-VPC workloads. AWS App Mesh is a service mesh based on the Envoy proxy. It standardises how applications communicate, giving you end-to-end visibility, and helping to ensure high-availability for your applications. A service mesh is composed of two parts, a control plane and a data plane. AWS App Mesh has a managed control plane so you as a user don’t need to install or manage any servers to run it. The data plane for App Mesh is the open source Envoy proxy. It is your responsibility to add the Envoy proxy as a side car to each application you want to expose and manage via App Mesh.

Fluent bit
Persistent storage for container logging using Fluent Bit and Amazon EFS Shrinath Kurdekar shows you how to persist logs from your Amazon Elastic Kubernetes Service (Amazon EKS) containers on highly durable, highly available, elastic, and POSIX-compliant Amazon Elastic File System (Amazon EFS) file systems using Fluent Bit. Fluent Bit is an open source log shipper and processor, that can collect data from multiple sources and forward it to different destinations for further analysis. Fluent Bit is a lightweight and performant log shipper and forwarder that is a successor to Fluentd and is a part of the Fluentd Ecosystem.

R
Bringing your own R environment to Amazon SageMaker Studio Nick Minaie and Sam Liu show you how you can add a custom R image to SageMaker Studio so you can build and train your R models with Amazon SageMaker. R is an open source software environment for statistical computing and graphics and the R language is widely used among statisticians and data miners for developing statistical software and data analysis. SageMaker Studio notebooks provide a set of built-in images for popular data science and ML frameworks and this post will show you how you can also add your own custom R images to SageMaker Studio so you can build and train your R models.

Partner / Industry spotlight
Public Sector
A new key to unlocking drug discovery Angela Wu takes a look at VirtualFlow, a new open-source software that is helping to narrow down and identify from the trillions of potential chemical compounds, which ones are best suited to help tackle a specific disease. Infectious disease specialists work to find the specific compound (key) that can bind to the right spot (lock) on a disease-enabling proteins to block its activity but the the key question they ask themselves is: which of the small molecule among the trillion is the right one for a specific disease? Given the range of possible molecule to protein combinations, finding the right small molecule that is able to bind strongly to a certain target site and inhibit its function is a time-intensive and challenging and this post explores how this new open source project, VirtualFlow is helping. Read on to find out more.
Case Studies and Industries
Graph databases
Building a biological knowledge graph at Pendulum using Amazon Neptune in this guest post, Connor Skennerton, Staff Data Engineer at Pendulum Therapeutics explores how graph databases provide an extremely flexible representation for the analysis of highly connected data in biotechnology. Amazon Neptune is a fast, reliable, fully managed graph database service that supports Apache TinkerPop Gremlin query language and Connor goes on to provide some examples of simple and more complex queries that are enabled thanks to the expressiveness of the Gremlin query language.
Other open source blog posts
PostgresSQL
PostgreSQL in AWS: clearing the doubts this post from AWS Data Hero Franck Pachot looks to clarify any doubts as to the nature of PostgresSQL on AWS, taking a look at some of the options you have, some of the features and what you need to look out for when rolling your own vs using managed services.
Delta Lake
Data Lakehousing in AWS George Pongracz who is a senior Data Engineer in the Enterprise DataOps Team at SEEK shares how they built a Data Lakehouse on AWS. After lifting and shifting their data warehouse to Amazon Redshift and ETL to Amazon EMR/PySpark, they took an opportunity to rethink and optimise their data platform as part of their CRM re-platform project. This combined Amazon Redshift and Delta Lake by creating a PySpark NoLoader program in conjunction with AWS services and a move from manual to automated processes, including the use of Apache Airflow for orchestration. For those perhaps unfamiliar with Delta Lake, it is an "open source columnar storage layer based on the Parquet file format. It provides ACID transactions and simplifies and facilitates the development of incremental data pipelines over cloud object stores like Amazon S3, beyond what is offered by Parquet whilst also providing schema evolution of tables."
As a bonus, you can dive even deeper by checking out George's talk How SEEK “Lakehouses” in AWS at Data Engineering AU Meetup

Kafka
Using ComposeX to deploy Confluent Kafka components great post from John Preston the maintainer of ECS ComposeX that shows you how you can use that project to deploy Confluent components in your own AWS VPC and ECS Clusters.
AWS Amplify
How will AWS Amplify (AWS Cloud) be going to make the Front-End Developer's life easy? Jaymit Bhoraniya provides a breakdown and overview of how AWS Amplify can help developers, and takes a look at the different capabilities and layers that AWS Amplify provides - whether it is the open source framework or how this works with the managed services provided by AWS, this should provide a quick primer to help you explore more.
Videos of the week
AWS CDK and Projen
Building AWS CDK Construct Library with Projen is a fantastic new video from Pahud Hsieh where he shows you how to build, test and publish AWS CDK construct from scratch with projen. After watching this video, you will be able to build your custom CDK construct and publish to npm and pypi.
kube-bench
AWS Security Hub integration with kube-bench Aqua Security VP of open source engineering Liz Rice shows you how to set up kube-bench to send information about failed or warning CIS Kubernetes Benchmark tests so that they appear as findings in AWS Security Hub.
AWS Amplify, Architect and React
Nader Dabit walks you through how to build a full stack serverless blogging app from scratch using Architect as the infrastructure as code provider and React on the client.
Quick Updates
PostgreSQL
PostgreSQL 13 is now available in the Amazon RDS Database Preview Environment, allowing customers to test PostgreSQL 13 on Amazon RDS. PostgreSQL 13 can now be deployed for development and testing in the Amazon RDS Database Preview Environment without the hassle of installing, provisioning, and managing the database. This release includes support for a number of extensions.
The PostgreSQL community released PostgreSQL 13 on September 24, 2020. PostgreSQL 13 includes improved functionality and performance such as better duplicate data handling by B-tree indexes, improvements added to partitioning functionality, incremental sorting to accelerate data sorts, parallel processing of indexes with the VACUUM command, more ways to monitor activity within a PostgreSQL database, new security capabilities, and more.
Porting Assistant for .NET
Porting Assistant for .NET can now support customers to migrate their legacy .NET framework applications to newly released .NET 5. .NET 5 is a major release with a broad set of features and improvements. With this updated release of Porting Assistant for .NET customers can analyze and port their .NET framework applications to either new release of .NET 5 or .NET Core 3.1. Porting Assistant for .NET is an analysis tool that scans .NET Framework applications and generates a .NET Core or .NET 5 compatibility assessment, helping you port your applications to Linux faster. Porting .NET Framework applications to .NET Core or .NET 5 helps customers take advantage of the performance, cost savings, and robust ecosystem of Linux.
The new, updated tool can be downloaded from here and existing customers can update to the latest version of the tool to take advantage of new capability.
PartiQL
You now can use PartiQL (a SQL-compatible query language)—in addition to already-available DynamoDB operations—to query, insert, update, and delete table data in Amazon DynamoDB. PartiQL makes it easier to interact with DynamoDB and run queries in the AWS Management Console. Because PartiQL is supported for all DynamoDB data-plane operations, it can help improve the productivity of developers by enabling them to use a familiar, structured query language to perform these operations. With PartiQL, DynamoDB continues to provide consistent, single-digit-millisecond latency at any scale. In addition, you can expect the same availability, latency, and performance when performing DynamoDB operations. The DynamoDB Service Level Agreement continues to apply while you use PartiQL to perform operations on DynamoDB table data.
AWS Batch now supports Amazon Linux 2
AWS Batch now supports natively launching Amazon Linux 2 as your AMI when creating an AWS Batch compute environment through a single parameter. Amazon Linux 2 is the next generation of Amazon Linux, a Linux server operating system from Amazon Web Services (AWS). It provides a secure, stable, and high performance execution environment to develop and run cloud and enterprise applications. With Amazon Linux 2, you get an application environment that offers long term support with access to the latest innovations in the Linux ecosystem.
AWS Batch enables developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS. AWS Batch dynamically provisions the optimal quantity and type of compute resources (e.g. CPU or memory optimized instances) based on the volume and specific resource requirements of the batch jobs submitted. When creating an AWS Batch compute environment, customers can simply select Amazon Linux 2 in the console, or specify AmazonLinux2 as the EC2 Configuration; which is a new parameter that is also introduced as part of this launch.
AWS Toolkit for JetBrains
The AWS Toolkit for JetBrains is an open source plugin for the integrated development environments (IDEs) from JetBrains that toolkit makes it easier to create, debug, and deploy software applications on Amazon Web Services in any of the JetBrains IDEs. The AWS Toolkit for JetBrains now provides convenient IDE functionality to interact with SQS queues and search through CloudWatch Logs.
Amazon SNS and SQS are foundational services used for synchronous service-to-service communication in serverless and microservices architectures. With pub/sub messaging you can design and build with event-driven architectures or decouple applications to increase performance, reliability and scalability. With the new release of the Toolkit, users can poll, publish messages, purge queues and configure triggers for Lambda functions, all from within the IDE. Check out the AWS Toolkit Docs to learn about the various SQS/SNS features in the IDE.
CloudWatch Logs Insights enables you to interactively search and analyze your log data in Amazon CloudWatch Logs. You can perform queries to help you more efficiently and effectively respond to operational issues. If an issue occurs, you can use CloudWatch Logs Insights to identify potential causes and validate deployed fixes. With the IDE integration customers can search their existing Cloudwatch Logs using the query API provided by Cloudwatch Logs Insights and view results listed in the results pane within the IDE. Check out the AWS Toolkit Docs to learn about the various CloudWatch Logs Insights features in the IDE.
Selenium
CloudWatch Synthetics now supports canary scripts in Python programming language with the Selenium open source web automation testing framework. This gives you more choice in the programming language and framework to use when creating canaries in CloudWatch Synthetics. Read more about this announcement here.
Lustre
Amazon FSx for Lustre, a service that provides high-performance shared storage, now enables you to increase the storage capacity of your file systems with the click of a button, providing you the flexibility to easily respond to your evolving storage needs by increasing file system size in a matter of minutes. Amazon FSx for Lustre makes it easy and cost effective to launch and run the world’s most popular high-performance file system in AWS. It is designed for applications that require fast storage – where you want your storage to keep up with your compute. Amazon FSx also integrates with Amazon S3, making it easy for you to process cloud data sets with the Lustre high-performance file system. You can now increase the storage capacity of your file systems as needed with the click of a button in the AWS Management Console or using an API call. With the new capability to grow storage, you can dynamically increase your storage size as your data sets grow, so you don't need to worry about accommodating growing data sets when creating your file system.
Events for your diary
re:Invent 2020
November 30th to December 18th
re:Invent starts later today, and for the next three weeks we will have a packed agenda featuring lots of great sessions covering open source projects from AWS and our customers and partners. It is FREE to attend and we have some amazing open source sessions as well as a dedicated open source track with unmissable content. I have linked above the posts that expand upon these sessions in more detail, but here is a list of the sessions over the next three weeks.
Open source track
- OPN 203: Redis 2020: Creating a Community-Driven Project
- OPN 305: Build real-time apps with Apache Flink
- OPN 206: Building End-To-End ML Workflows with Kubeflow Pipelines
- OPN 301: Open Source Observability at AWS
- OPN 302: The Serverless LAMP stack
- OPN 303: Open Source Meets SaaS: Accelerating the Path to SaaS Adoption
- OPN 304: Open source failure injection on AWS
- OPN 201: Introduction to GraphQL
- OPN 204: Accelerate that App! with Amplify opensource framework
- OPN 202: App modernization on AWS with Apache Kafka & Confluent Cloud
Other open source sessions
- ADM 301 Running ultra-high throughput ad tech workloads on Aerospike
- AIM 313 Scaling MLOps on Kubernetes with Amazon SageMaker Operators
- AIM 402 Fast distributed training and near-linear scaling with PyTorch on AWS
- AIM 404 Productionizing R workloads using Amazon SageMaker, featuring Siemens
- AIM 405 Train large models with billions of parameters in TensorFlow 2.0
- ARC 307 Going global in minutes: Multi-Region expansion simplified
- CMP 206 HPC on AWS: Innovating without infrastructure constraints
- CON 201 Getting an insight into your Kubernetes applications
- CON 202 AWS Copilot: Simplifying container development
- CON 207 Define AWS service resources with AWS Controllers for Kubernetes
- CON 211 Red Hat OpenShift Service on AWS
- DAT 314 Running Apache Cassandra workloads with Amazon Keyspaces
- DOP 202 AWS CDK: What’s new and what’s next
- FWM 201 Power modern serverless applications with GraphQL and AWS AppSync
- FMW 202 Empower front-end web and mobile app development with AWS Amplify
- FMW 303 Build iOS & Android mobile apps in record time with Flutter and AWS Amplify
- FMW 304 Unify access to siloed data with AWS AppSync GraphQL resolvers
- FMW 306 Best practices to securely operate GraphQL at scale with AWS AppSync
- IOT 303 Developing and deploying modern edge applications at scale
- NFX 302 Simplifying delivery as code with Spinnaker and Kubernetes
Virtual ROS-Industrial Conference 2020
December 15 - 16, 2020
The 8th edition of ROS-Industrial Conference will be held as a virtual event. It is not only the annual community meeting for the European ROS-Industrial community but this years event is also the final event of the H2020 ROSIN project. The conference gives you the chance to see the newest technical developments and to meet people and companies, which are active in the ROS community.
Learn more and sign up here.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen.
Your feedback matters!
I have put together a short feedback survey, which I would ask you to take - it will take no more than 2 minutes. You can access here. Many thanks!





Top comments (0)