AWS Big Data Blog
Query an Apache Hudi dataset in an Amazon S3 data lake with Amazon Athena part 1: Read-optimized queries
July 2023: This post was reviewed for accuracy.
On July 16, 2021, Amazon Athena upgraded its Apache Hudi integration with new features and support for Hudi’s latest 0.8.0 release. Hudi is an open-source storage management framework that provides incremental data processing primitives for Hadoop-compatible data lakes. This upgraded integration adds the latest community improvements to Hudi along with important new features including snapshot queries, which provide near real-time views of table data, and reading bootstrapped tables which provide efficient migration of existing table data.
In this series of posts on Athena and Hudi, we will provide a short overview of key Hudi capabilities along with detailed procedures for using read-optimized queries, snapshot queries, and bootstrapped tables.
Overview
With Apache Hudi, you can perform record-level inserts, updates, and deletes on Amazon S3, allowing you to comply with data privacy laws, consume real-time streams and change data captures, reinstate late-arriving data, and track history and rollbacks in an open, vendor neutral format. Apache Hudi uses Apache Parquet and Apache Avro storage formats for data storage, and includes built-in integrations with Apache Spark, Apache Hive, and Apache Presto, which enables you to query Apache Hudi datasets using the same tools that you use today with near-real-time access to fresh data.
An Apache Hudi dataset can be one of the following table types:
- Copy on Write (CoW) – Data is stored in columnar format (Parquet), and each update creates a new version of the base file on a write commit. A CoW table type typically lends itself to read-heavy workloads on data that changes less frequently.
- Merge on Read (MoR) – Data is stored using a combination of columnar (Parquet) and row-based (Avro) formats. Updates are logged to row-based delta files and are compacted as needed to create new versions of the columnar files. A MoR table type is typically suited for write-heavy or change-heavy workloads with fewer reads.
Apache Hudi provides three logical views for accessing data:
- Read-optimized – Provides the latest committed dataset from CoW tables and the latest compacted dataset from MoR tables
- Incremental – Provides a change stream between two actions out of a CoW dataset to feed downstream jobs and extract, transform, load (ETL) workflows
- Real-time – Provides the latest committed data from a MoR table by merging the columnar and row-based files inline
As of this writing, Athena supports read-optimized and real-time views.
Using read-optimized queries
In this post, you will use Athena to query an Apache Hudi read-optimized view on data residing in Amazon S3. The walkthrough includes the following high-level steps:
- Store raw data in an S3 data lake.
- Transform the raw data to Apache Hudi CoW and MoR tables using Apache Spark on Amazon EMR.
- Query and analyze the tables on Amazon S3 with Athena on a read-optimized view.
- Perform an update to a row in the Apache Hudi dataset.
- Query and analyze the updated dataset using Athena.
Architecture
The following diagram illustrates our solution architecture.
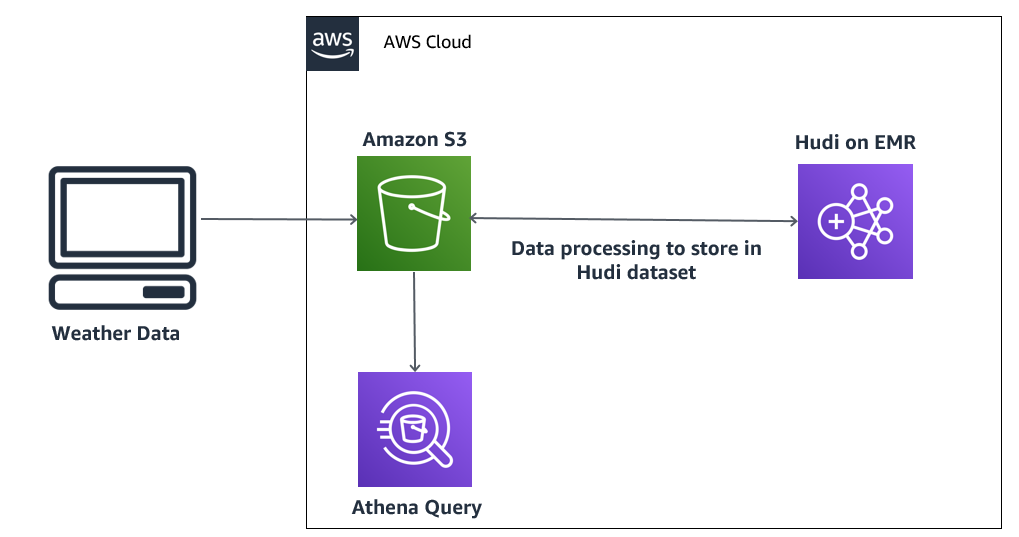
In this architecture, you have high-velocity weather data stored in an S3 data lake. This raw dataset is processed on Amazon EMR and stored in an Apache Hudi dataset in Amazon S3 for further analysis by Athena. If the data is updated, Apache Hudi performs an update on the existing record, and these updates are reflected in the results fetched by the Athena query.
Let’s build this architecture.
Prerequisites
Before getting started, we set up our resources. For this post, we use the us-east-1 Region.
- Create an Amazon Elastic Compute Cloud (Amazon EC2) key pair. For instructions, see Create a key pair using Amazon EC2.
- Create a S3 bucket for storing the raw weather data (for this post, we call it
weather-raw-bucket). - Create two folders in the S3 bucket:
parquet_fileanddelta_parquet. - Download all the data files, Apache Scala scripts (
data_insertion_cow_delta_script,data_insertion_cow_script,data_insertion_mor_delta_script, anddata_insertion_mor_script), and Athena DDL code (athena_weather_hudi_cow.sqlandathena_weather_hudi_mor.sql) from the GitHub repo. - Upload the
weather_oct_2020.parquetfile toweather-raw-bucket/parquet_file. - Upload the file
weather_delta.parquettoweather-raw-bucket/delta_parquet. We update an existing weather record from arelative_humidityof81to50and a temperature of6.4to10. - Create another S3 bucket for storing the Apache Hudi dataset. For this post, we create a bucket with a corresponding subfolder named
athena-hudi-bucket/hudi_weather. - Deploy the EMR cluster using the provided AWS CloudFormation template:

- Enter a name for your stack.
- Choose a pre-created key pair name.
This is required to connect to the EMR cluster nodes. For more information, see Connect to the Master Node Using SSH.
- Accept all the defaults and choose Next.
- Acknowledge that AWS CloudFormation might create AWS Identity and Access Management (IAM) resources.
- Choose Create stack.
Use Apache Hudi with Amazon EMR
When the cluster is ready, you can use the provided key pair to SSH into the primary node.
- Use the following bash command to load the
spark-shellto work with Apache Hudi: - On the
spark-shell, run the following Scala code in the scriptdata_insertion_cow_scriptto import weather data from the S3 data lake to an Apache Hudi dataset using the CoW storage type:
Replace the S3 bucket path for inputDataPath and hudiTablePath in the preceding code with your S3 bucket.
For more information about DataSourceWriteOptions, see Work with a Hudi Dataset.
- In the
spark-shell, count the total number of records in the Apache Hudi dataset: - Repeat the same step for creating an MoR table using
data_insertion_mor_script(the default isCOPY_ON_WRITE). - Run the
spark.sql("show tables").show();query to list three tables, one for CoW and two queries,_rtand _ro, for MoR.
The following screenshot shows our output.

Let’s check the processed Apache Hudi dataset in the S3 data lake.
- On the Amazon S3 console, confirm the subfolders
weather_hudi_cowandweather_hudi_morare inathena-hudi-bucket.

- Navigate to the
weather_hudi_cowsubfolder to see the Apache Hudi dataset that is partitioned using thedatekey—one for each date in our dataset.

- On the Athena console, create a
hudi_athena_testdatabase using following command:
You use this database to create all your tables.
- Create an Athena table using the
athena_weather_hudi_cow.sqlscript:
Replace the S3 bucket path in the preceding code with your S3 bucket (Hudi table path) in LOCATION.

- Add partitions to the table by running the following query from the
athena_weather_judi_cow.sqlscript on the Athena console:
Replace the S3 bucket path in the preceding code with your S3 bucket (Hudi table path) in LOCATION.
- Confirm the total number of records in the Apache Hudi dataset with the following query:
It should return a single row with a count of 1,000.

Now let’s check the record that we want to update.
- Run the following query on the Athena console:
The output should look like the following screenshot. Note the value of relative_humidity and temperature.

- Return to the Amazon EMR primary node and run the following code in the
data_insertion_cow_delta_scriptscript on thespark-shellprompt to update the data:
Replace the S3 bucket path for inputDataPath and hudiTablePath in the preceding code with your S3 bucket.
- Run the following query on the Athena console to confirm no change occurred to the total number of records:
The following screenshot shows our query results.

- Run the following query again on the Athena console to check for the update:
The relative_humidity and temperature values for the relevant record are updated.

- Repeat similar steps for the MoR table.
Clean up the resources
You must clean up the resources you created earlier to avoid ongoing charges.
- On the AWS CloudFormation console, delete the stack you launched.
- On the Amazon S3 console, empty the buckets
weather-raw-bucketandathena-hudi-bucketand delete the buckets.
Conclusion
As you have learned in this post, we used Apache Hudi support in Amazon EMR to develop a data pipeline to simplify incremental data management use cases that require record-level insert and update operations. We used Athena to read the read-optimized view of an Apache Hudi dataset in an S3 data lake.
About the Authors
 Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration and strategy. He is passionate about technology and enjoys building and experimenting in Analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration and strategy. He is passionate about technology and enjoys building and experimenting in Analytics and AI/ML space.
 Sameer Goel is a Solutions Architect in The Netherlands, who drives customer success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with a master’s degree from NEU Boston, with a Data Science concentration. He enjoys building and experimenting with creative projects and applications.
Sameer Goel is a Solutions Architect in The Netherlands, who drives customer success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with a master’s degree from NEU Boston, with a Data Science concentration. He enjoys building and experimenting with creative projects and applications.
 Imtiaz (Taz) Sayed is the WW Tech Leader for Analytics at AWS. He enjoys engaging with the community on all things data and analytics.
Imtiaz (Taz) Sayed is the WW Tech Leader for Analytics at AWS. He enjoys engaging with the community on all things data and analytics.